Feb 6, 2026
Publication
gWorld: The first-of-its-kind mobile world model

요약 — gWorld는 스마트폰의 다음 화면을 HTML/CSS 코드로 예측하는 오픈소스 모바일 월드 모델입니다. 8B 모델 하나로 50배 더 큰 모델들을 이겼습니다.
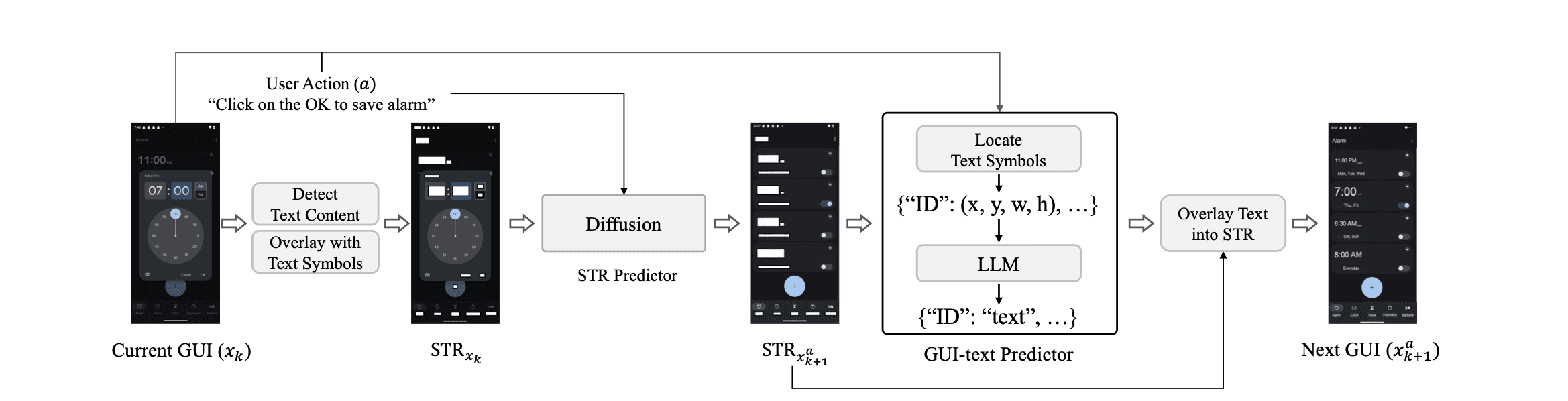
모바일 월드 모델은 스크린샷 한 장과 동작 하나(예: [350, 720] 좌표 탭)를 받아서 다음 화면이 어떻게 바뀔지 예측합니다. "이 버튼을 누르면 화면이 어떻게 될까?"에 대한 답을 데이터로부터 학습한 것입니다. 구글의 Genie 3같은 월드 모델과 같은 개념이지만, 대상이 모바일 GUI입니다. 이 예측이 충분히 정확하다면? 실제 폰 없이도 "탭 → 스와이프 → 입력"같은 일련의 조작을 통째로 시뮬레이션할 수 있습니다. 휴대폰을 조작하는 AI 에이전트를 훈련시키는 데 핵심적인 인프라입니다.
그런데 현재의 접근법들은 두 가지 불완전한 선택지 사이에 갇혀 있습니다. 텍스트 기반 월드 모델은 레이아웃, 색상, 타이포그래피 같은 시각 정보를 통째로 버립니다. 풍부한 인터페이스가 평면적인 설명으로 축소됩니다. 이미지 생성 모델은 픽셀을 직접 만들어내려 하지만, 텍스트 렌더링을 왜곡하고 모바일 UI의 정밀한 구조를 놓칩니다. 어느 쪽도 충분하지 않습니다.
우리는 이 딜레마에서 빠져나오기 위해 gWorld를 만들었습니다. 텍스트 설명도 아니고 원시 픽셀도 아닌, 다음 화면 상태를 렌더링 가능한 웹 코드로 예측합니다. 이는 매우 단순하면서도 자연스러운 발상입니다. VLM은 사전 훈련을 통해 이미 구조화된 코드를 이해하고 있고, 웹 코드는 픽셀 생성기가 재현하지 못하는 시각적 세부사항 — 픽셀 단위로 완벽한 텍스트, 정확한 레이아웃, 적절한 아이콘 — 을 그대로 보존합니다.
다음 화면 예측이 중요한 이유
2026년 현재, AI로 휴대폰이나 컴퓨터를 직접 조작하는 도구들이 쏟아지고 있습니다. GitHub 스타 24만 개를 찍은 OpenClaw, Anthropic의 Claude Computer Use, Manus AI까지. 그런데 실제로 써본 사람이라면 공감할 겁니다 — 느리고, 자주 틀립니다. 스크린샷 캡처 → VLM 추론 → 액션 실행의 루프를 매번 반복하는데, Anthropic조차 자사 문서에서 "현재 레이턴시가 일반 사용에 비해 너무 느리다"고 인정합니다. 느린 것도 문제지만, 더 본질적인 문제는 잘못된 행동의 비용입니다. 에이전트가 틀린 버튼을 누르면 되돌리기 어렵고, 때로는 불가능합니다.
이 에이전트들을 더 똑똑하게 만들려면 대규모 훈련이 필요한데, 훈련 환경 자체가 병목입니다. 매 동작마다 에뮬레이터 응답을 기다려야 하고, 에이전트 하나를 훈련시키려면 기기 하나가 통째로 점유되어 수백 개를 동시에 돌릴 수가 없습니다. 훈련 중 에이전트가 실수로 금융 거래를 확정하는 상황도 허용할 수 없습니다.
월드 모델은 두 문제를 동시에 해결합니다. 각 동작의 결과를 정확히 시뮬레이션해서, 실제 기기 없이 가상의 조작 경로를 무한히 만들어내는 상상 속 에이전트 훈련을 가능하게 합니다. 수백 개의 시나리오를 동시에 탐색하고, 위험한 작업도 안전하게 연습하고, GUI 에이전트를 위한 대규모 강화 학습을 돌릴 수 있습니다. 모두 여기서 시작됩니다.
단, 월드 모델은 충분히 정확해야 합니다. 텍스트를 잘못 생성하거나 레이아웃을 왜곡하거나 동작의 실제 결과를 반영하지 못하면, 그 위에서 학습하는 에이전트도 망가집니다. 시각적 정확도는 선택 사항이 아닙니다.
기존 방법의 한계
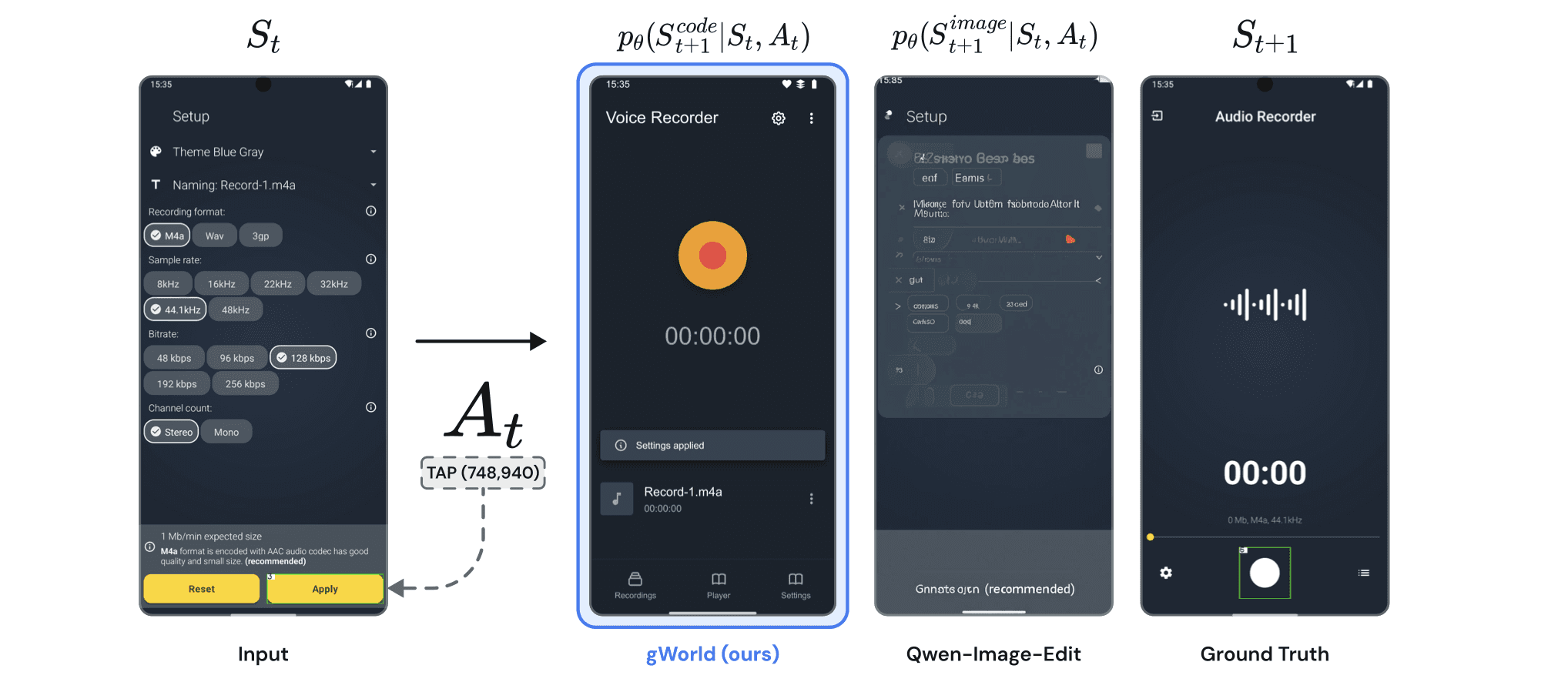
gWorld 이전에 시각적 모바일 월드 모델링의 가장 야심찬 시도는 VIMO였습니다. 맞춤 훈련된 Diffusion 모델로 다음 상태 이미지를 생성하는 방식입니다. 시각적 월드 모델이 텍스트 모델보다 우수하다는 점은 입증했지만, 심각한 한계가 있었습니다. VIMO의 파이프라인은 OCR, 박스 기반 텍스트 마스킹, 필터링 및 텍스트 보완용 GPT-4o, 이미지 생성용 Diffusion 모델 등 총 5개의 별도 모델이 협업해야 합니다. 복잡하고 느리고 비쌉니다. 해당 모델의 가중치는 공개된 적도 없습니다.
더 근본적인 문제가 있습니다. 이미지 생성 모델은 모바일 GUI에서 구조적 약점을 드러냅니다. 휴대폰 화면은 동작 전후로 거의 바뀌지 않습니다. 탭 한 번으로 토글 하나가 바뀌거나 작은 메뉴가 열리지만 화면의 90%는 그대로입니다. 이미지 생성 모델은 이걸 악용합니다 — 입력 이미지를 거의 그대로 복사하고 사소한 수정만 가하는 지름길을 학습하는 겁니다. 두 이미지가 얼마나 비슷하게 보이는지 측정하는 지표에서는 높은 점수가 나오지만, 정작 변경된 부분은 포착하지 못합니다.
이는 수치로 확인할 수 있습니다. 출력 품질이 "원래 화면과 다음 화면이 얼마나 비슷한지"에 어느 정도 의존하는지 상관관계를 측정했을 때, 이미지 생성 모델은 0.9 이상 — 거의 완벽한 상관관계를 보입니다. 쉽게 말해, 화면이 별로 안 바뀌는 쉬운 경우에만 잘하고, 실제로 큰 변화가 있는 경우엔 틀린다는 뜻입니다. gWorld의 상관관계는 약 0.4. 원래 화면이 비슷하든 다르든 상관없이, 실제로 바뀐 부분을 정확히 잡아냅니다.
코드의 시각적 표현: 핵심 아이디어
gWorld의 핵심 통찰은 단순합니다. 모바일 GUI 상태를 표현하는 데 웹 코드가 텍스트나 픽셀보다 낫다는 것.
휴대폰 화면을 생각해 보면, 정밀한 공간 규칙에 따라 배열된 텍스트, 아이콘, 상호작용 요소의 구조화된 레이아웃입니다. 사실상 HTML과 CSS의 역할과 같습니다. VLM을 훈련시켜 픽셀 대신 렌더링 가능한 웹 코드를 출력하게 하면 두 가지 장점을 동시에 확보할 수 있습니다.
VLM은 정확하고 읽기 좋은 텍스트를 생성하는 데 이미 강합니다 — Diffusion 모델이 특히 못 하는 부분입니다. 수십억 웹 페이지로 사전 훈련된 덕에 시각적 레이아웃을 구조화된 코드로 변환하는 방법도 알고 있습니다. 또한, 출력이 실행 가능합니다. 헤드리스 브라우저에서 HTML을 렌더링하면(Playwright 기준 약 0.3초) 픽셀 단위로 완벽한 스크린샷이 나옵니다. gWorld 출력 중 렌더링 실패는 1% 미만. 구조적 오류가 사실상 없습니다.
한 끗 차이지만 강력한 효과가 있습니다. 모델이 단순한 레이아웃이 아닌 의미적으로 일관된 콘텐츠를 생성한다는 점입니다. 이메일 앱의 다음 상태를 예측할 때 gWorld는 맥락에 맞는 설득력 있는 이메일 본문을 생성합니다. 설정 화면에서는 토글 라벨과 옵션 값이 상황에 맞게 조정됩니다. 기반 VLM의 언어 능력이 그대로 전이되는 것 — 순수 이미지 생성기로는 불가능한 방식입니다.
MWMBench: 모바일 월드 모델을 위한 벤치마크
기존 모바일 월드 모델링 벤치마크에는 사각지대가 있었습니다. "화면 중앙 탭"처럼 좌표를 텍스트 설명으로 바꿔서 평가하거나, 훈련 때 본 앱에서만 테스트하거나, 시각적 출력이 아닌 텍스트 출력만 평가하는 식이었습니다.
세 가지 문제를 모두 해결하기 위해 MWMBench를 설계했습니다. 훈련 때 본 앱 4종, 한 번도 본 적 없는 앱 2종 — 총 6개 데이터 소스를 포괄하며, 행동을 원본 좌표 형식으로 유지하고 시각적 월드 모델링을 직접 평가합니다. 특히 중요한 건 "본 적 없는 앱"에서의 성능입니다. AndroidWorld는 영어 생산성·미디어 앱에서 처음 보는 화면을 얼마나 잘 예측하는지 테스트하고, KApps는 배민, 쿠팡, 카카오톡, 네이버 지도 등 한국어 인터페이스로의 일반화를 테스트합니다. 한국의 실제 모바일 사용 패턴을 반영한 벤치마크입니다.
핵심 평가 지표는 IAcc(Instruction Accuracy)입니다. 세 가지 Frontier VLM이 심사위원으로서, 생성된 다음 상태가 동작의 결과를 올바르게 반영하는지 판단합니다. 앞서 설명한 픽셀 유사도보다 훨씬 엄격한 기준입니다.
결과: 소형 모델로 50배 큰 모델을 압도하는 성과
gWorld 32B는 6개 벤치마크 전체에서 가장 높은 평균 IAcc를 달성했습니다. gWorld 8B가 바짝 뒤를 따릅니다. 두 모델 모두 테스트한 모든 프론티어 오픈웨이트 모델을 능가합니다 — Llama 4 402B(50배 큰 모델), Qwen3 VL 235B(29배), GLM-4.6V 106B(13배) 포함.
코드 기반 접근법은 렌더링 실패를 사실상 제거합니다. gWorld의 실패율은 1% 미만인 반면, 이미지 생성 베이스라인은 두 자릿수 실패율을 기록합니다. 처음 보는 앱에서도 gWorld는 훈련 때 본 앱 대비 최소한의 성능 저하만 보입니다. 특정 앱을 외운 게 아니라 진짜로 일반화했다는 강력한 증거입니다.
데이터를 늘리면 성능도 따라오는지도 확인했습니다. 결과는 명확합니다 — 데이터가 늘어날수록 성능이 예측 가능하게 올라가고(R² ≥ 0.94), 아직 천장에 닿지 않았습니다. 현재 26만 개 전환만 사용했는데, 기존 데이터셋에서 뽑아낼 수 있는 전환은 370만 개입니다. 데이터를 더 만드는 것만으로도 상당한 성능 향상 여지가 남아 있습니다.
월드 모델에서 더 나은 에이전트로
핵심 질문 — 더 나은 월드 모델이 실제로 더 나은 에이전트를 만드는가? gWorld를 모바일 에이전트 프레임워크 M3A에 통합하고 실험했습니다. 방식은 이렇습니다: 에이전트가 다음 행동 후보 3개를 놓고, gWorld로 각각의 결과 화면을 미리 시뮬레이션한 뒤, 가장 나은 결과가 예상되는 행동을 선택합니다. 행동하기 전에 머릿속으로 먼저 해보는 셈입니다.
두 가지 백본 정책(Gemini 2.5 Flash, GPT-5 Mini)에 gWorld 8B를 얹었을 때 가장 큰 개선이 나타났습니다 — 각각 +22.4, +21.8 퍼센트 포인트. 월드 모델링 성능 1%p 향상이 에이전트 정책 성능 약 0.49%p 개선으로 이어집니다. 월드 모델의 품질이 에이전트 능력에 직접 영향을 미친다는, 측정 가능한 증거입니다.
알리바바 Code2World
gWorld 논문 공개 직후, 알리바바 AMAP 팀이 Code2World를 발표했습니다. 핵심 아이디어가 놀라울 정도로 같습니다 — GUI 월드 모델을 렌더링 가능한 HTML 코드 생성으로 접근하고, Diffusion 모델의 픽셀 생성 방식을 코드로 대체한다는 것. Code2World는 발표 후 큰 주목을 받았습니다.
우리는 이를 경쟁이 아닌 검증으로 봅니다. 독립적인 두 팀이 같은 시기에 같은 해법에 도달했다는 것은, "코드 생성 기반 GUI 월드 모델"이라는 패러다임이 이 문제의 자연스러운 해답임을 강하게 시사합니다.
gWorld를 직접 사용해보세요
gWorld는 Hugging Face를 통해 모델, 데이터 파이프라인, 벤치마크가 모두 Apache 2.0으로 공개되어 있습니다. 연구, 파인튜닝, 에이전트 통합까지 자유롭게 활용하실 수 있습니다.
프로젝트 페이지: trillionlabs-gworld.github.io
모델: gWorld-8B | gWorld-32B
벤치마크: MWMBench
Trillion Labs는 LLM 과 AI 에이전트의 기초 역량을 만드는 팀입니다. 관심 있으신 분은 채용 페이지를 확인해주세요.
Read more from our blog


Join our newsletter
Get the latest AI news and insights every week