March 18, 2025
Model Release
Introducing Tri-7B

트릴리온 랩스의 첫 자체 LLM, Tri-7B-preview를 공개합니다. 이 모델은 다국어 확장성과 성능의 한계를 뛰어넘기 위해 설계되었으며, Pre-training 부터 from-scratch 로 학습되었습니다.
특히, 데이터가 풍부한 언어와 부족한 언어 사이의 간극을 해결하기 위해 Cross-lingual Document Attention (XLDA)이라는 아키텍처를 도입하였습니다. 결과적으로, Tri-7B-Preview 는 연산 비용과 토큰 소모를 획기적으로 줄이면서도 압도적인 다국어 벤치마크 성능을 보여줍니다.
단 2억 원으로 일궈낸 성과: 가성비와 성능을 모두 잡은 Tri-7B
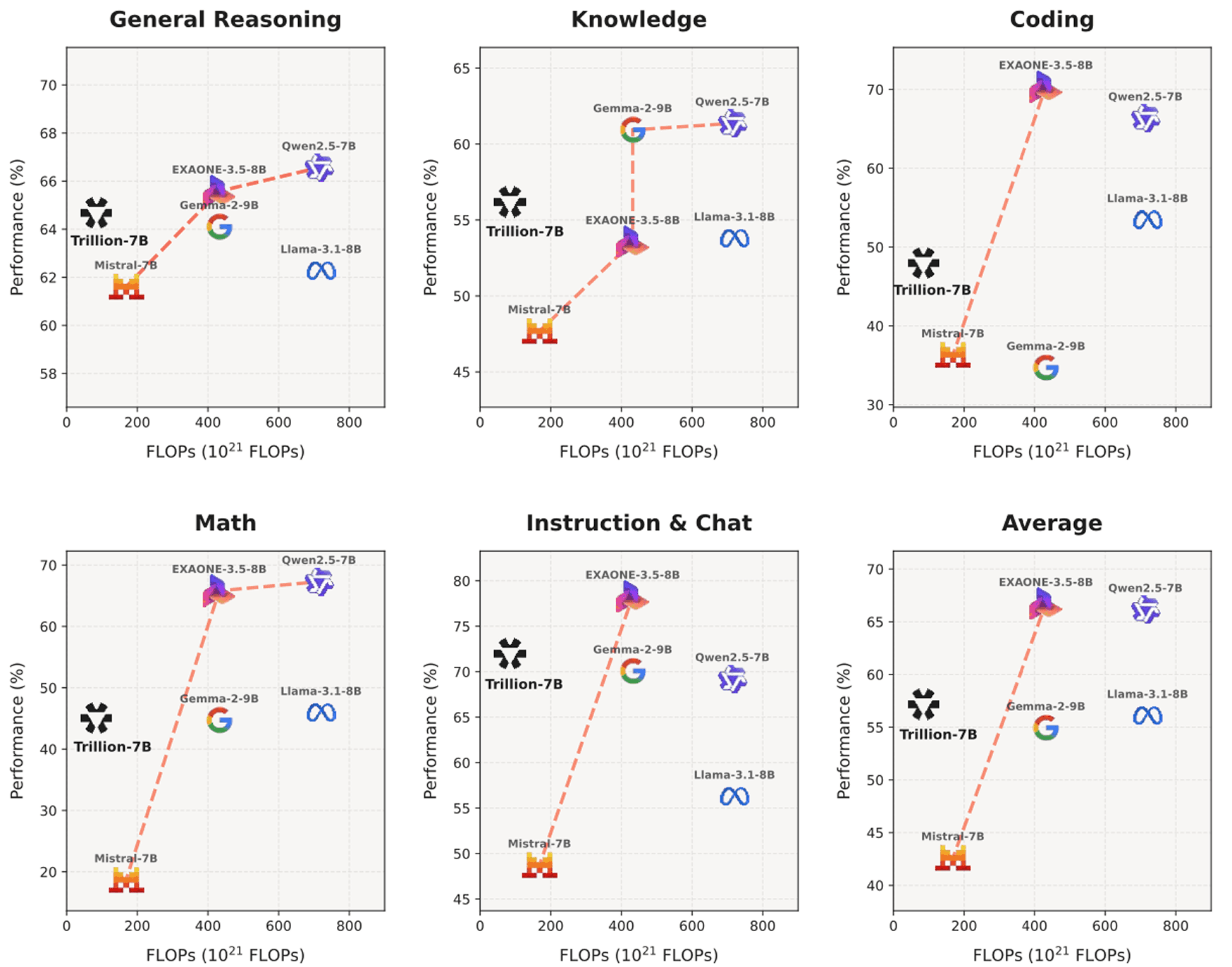
Tri-7B는 모든 측면에서 Compute Pareto-frontier를 유의미하게 앞당깁니다.
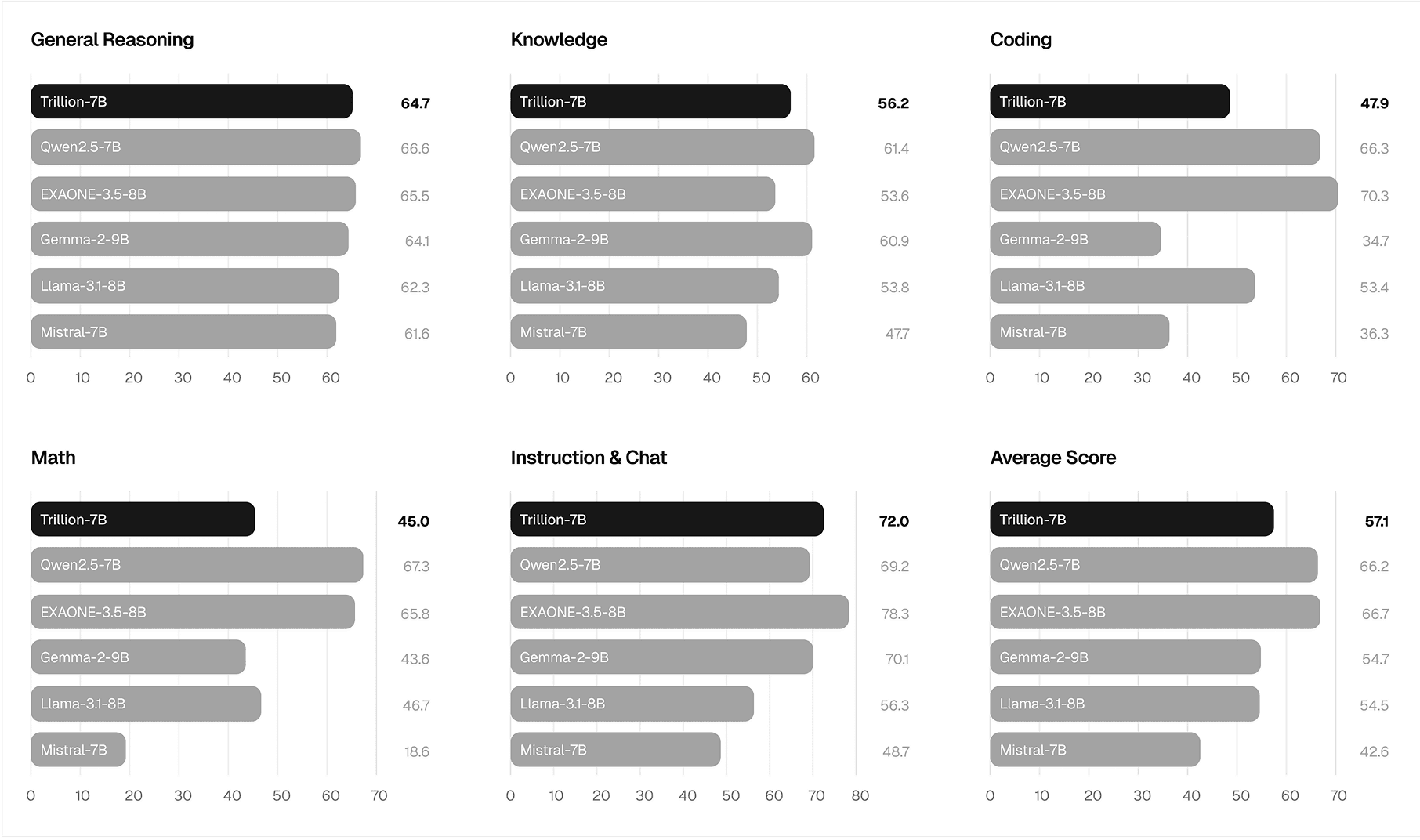
학습 FLOPs 대비 성능을 타 모델과 비교했을 때, Tri-7B-preview는 Pareto Frontier를 새롭게 정의하고 있습니다. 본 모델은 약 9.3×1022 FLOPs라는 현저히 적은 연산량만으로도 평균 55.7%의 성능을 달성했습니다. 이는 Mistral-7B-Instruct-v0.3이나 SOLAR-10.7B-Instruct-v1.0의 성능을 상회하는 수치입니다. 또한 Qwen2.5-7B-Instruct나 EXAONE-3.5-7.8B-Instruct처럼 3~8배 더 많은 연산 자원을 소모하는 모델들과 대등한 수준의 경쟁력을 보여줍니다.
비용 측면에서 보면, Tri-7B의 학습 비용은 H100 GPU 기준 약 5.94만 시간, 금액으로는 약 14.8만 달러($) 수준에 불과합니다. 이는 저희의 접근 방식이 컴퓨팅 효율성 면에서 얼마나 압도적인지를 입증합니다.
다국어 성능의 핵심: Cross-lingual Document Attention (XLDA)
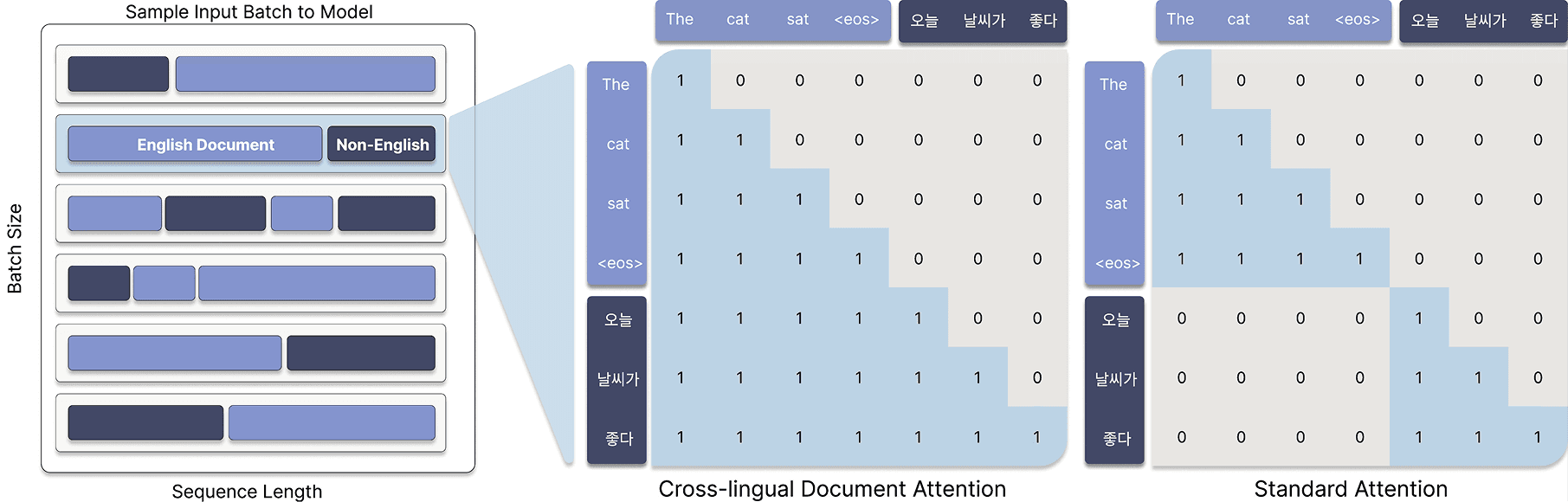
Cross-lingual Document Attention (XLDA)
Tri-7B 다국어 성능의 핵심에는 XLDA (Cross-lingual Document Attention)가 있습니다. XLDA는 방대한 다국어 코퍼스 없이도 언어 간 지식 전이를 원활하게 만드는 기술입니다.
XLDA는 전략적인 문서 구성과 선택적 어텐션 마스킹을 결합한 방식으로 작동합니다. 간단히 말하면, 학습 과정에서 각 입력 시퀀스를 의도적으로 여러 언어(예: 영어와 한국어)의 콘텐츠로 채웁니다. 이렇게 함으로써 모델은 같은 맥락 안에서도 다양한 언어 간의 패턴을 배울 수 있게 됩니다.
기존의 방법에서는 문서 경계를 넘으면 어텐션이 차단되는 경우가 많았지만, XLDA는 다릅니다. 서로 다른 언어의 단어들이 서로를 참조할 수 있도록 허용하여, 모델이 여러 언어의 정보를 의미적으로 연결하고 결합할 수 있게 합니다. 결과적으로, 모델은 다언어 환경에서 더 정확하고 통합적인 이해를 할 수 있게 되는 것이죠.
이 접근법은 특히 다국어 처리에서 효율성을 높이면서도 성능을 유지하는 데 중점을 둡니다.
Llama 3.1을 압도하는 다국어 일관성
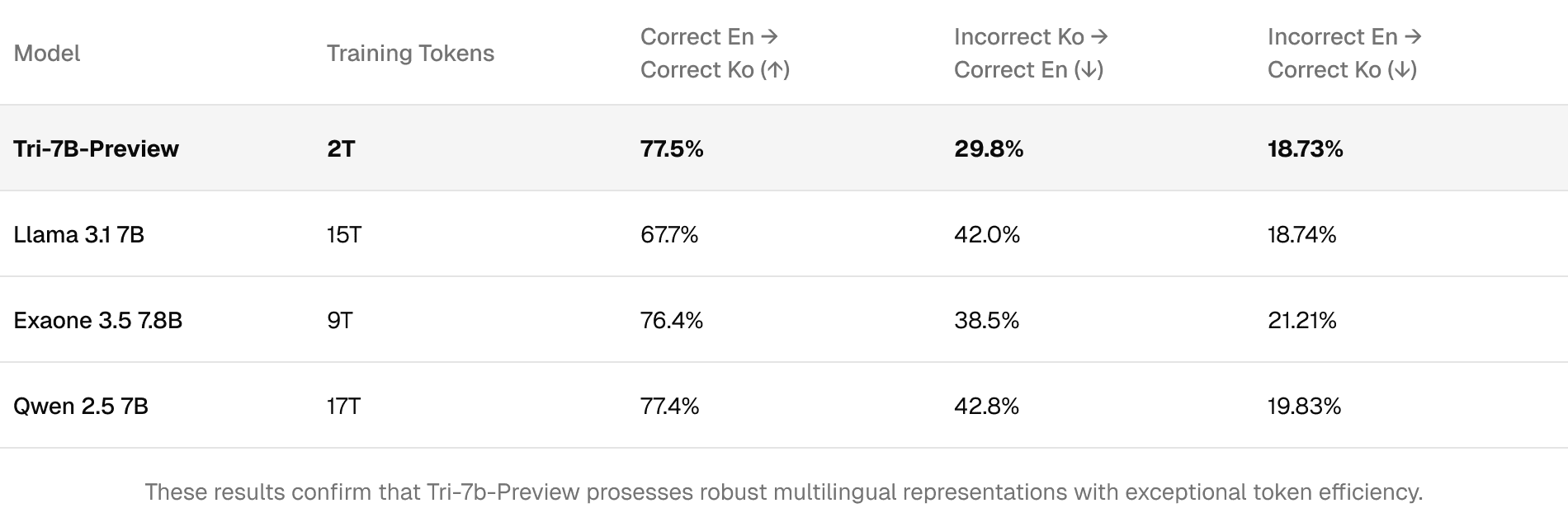
저희는 Global-MMLU의 영-한 질문 세트를 활용해 언어 간 지식 전이가 얼마나 잘 이루어지는지 평가했습니다. 주요 지표는 '영어로 정답을 맞힌 문제가 한국어에서도 정답으로 이어지는지'를 측정하는 일관성입니다.
Tri-7B는 77.5%의 언어 간 일관성을 기록하며 Qwen 2.5 7B와 대등한 수준의 성능을 보였습니다. 주목할 점은 Tri-7B가 8.5배 더 적은 학습 토큰을 사용하고도 Llama 3.1 7B(67.7%)를 크게 앞질렀다는 것입니다.
이러한 결과는 Tri-7B-Preview가 독보적인 토큰 효율성을 바탕으로 매우 견고한 다국어 표현 능력을 갖추고 있음을 증명합니다.
비전 영역으로의 확장성
Tri-7B가 가진 다국어 모델로서의 강점은 텍스트를 넘어 Vision-Language 태스크에서도 빛을 발합니다. LLaVA 학습 프레임워크를 기반으로 Tri-7B를 비전 언어 모델 (VLM) 로 파인튜닝했습니다. 이때 학습 데이터로는 오직 영어로 된 Vision-language instruction 쌍만을 사용했습니다.
놀라운 점은 비전 학습을 영어로만 진행했음에도 불구하고, Trillion-LLaVA가 한국어 시각 추론에서 뛰어난 제로샷(Zero-shot) 성능을 보였다는 것입니다. 실제로 한국어 관련 벤치마크에서 다른 7B급 VLM들을 큰 차이로 앞질렀습니다.
이 결과는 사전 학습 단계에서 다국어 기초를 탄탄히 다져 놓으면, 특정 언어의 이미지 학습 데이터가 없어도 언어 간 시각적 추론 전이가 충분히 가능하다는 것을 증명합니다. 결과적으로 다국어 비전 시스템을 구축하는 과정을 훨씬 더 효율적으로 단축할 수 있는 길을 열어준 셈입니다.

지금 바로 Tri-7B-Preview를 만나보세요!
Tri-7B-Preview에 대해 더 자세히 알고 싶다면 아래 링크를 확인해 주세요.
🤗 Hugging Face 모델 카드: Hugging Face에서 Tri-7B-Preview 확인하기
📄 기술 리포트: 아키텍처와 학습 방법론에 대한 상세 내용은 Tri-7B 기술 리포트에서 읽어보실 수 있습니다.
Read more from our blog


Join our newsletter
Get the latest AI news and insights every week