November 28, 2025
Tech Blog
Tri-Series 7B, 21B, 그리고 70B ① : 설립 1년차 스타트업이 국내 최대 규모의 LLM을 만든다는 것

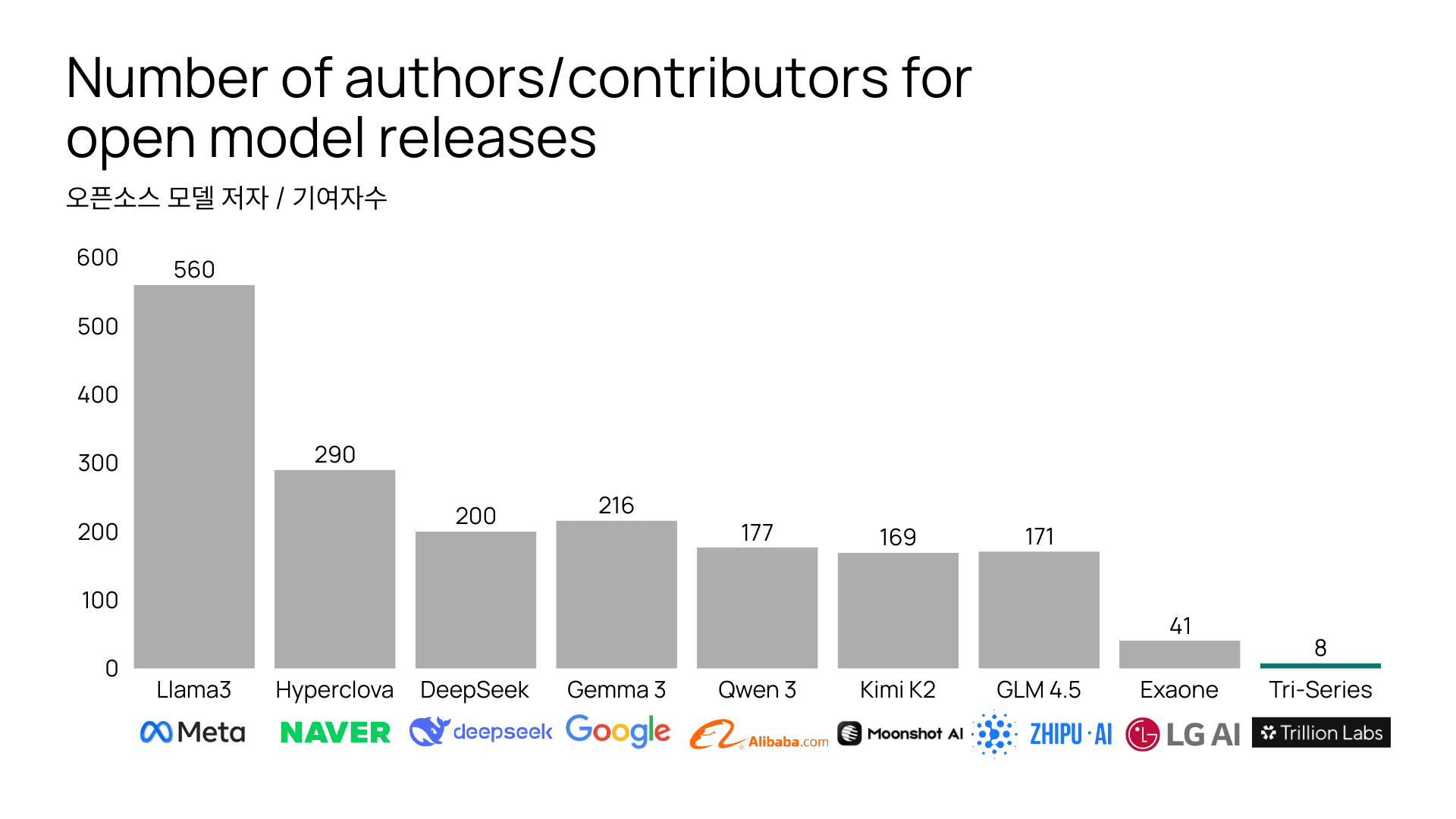
메타 Llama3 - 560명, 네이버 Hyperclova - 290명, 딥시크 - 200명, 구글 Gemma3 - 216명, 알리바바 Qwen 3 - 177명, Moonshot AI Kimi K2 - 169명, Zhipu AI GLM 4.5 - 171명, LG AI 리서치 Exaone - 41명
그리고 Trillion Labs - 8명
수백 명이 투입되고, 수천억 원의 비용이 들어간 LLM들이 매일같이 쏟아지고 있는 지금, Trillion Labs는 단 8명의 개발자만으로 7B, 21B, 그리고 70B에 이르는 국내 최대 규모의 LLM 시리즈, Tri-Series를 직접 설계하고 학습해 오픈소스로 공개했습니다. 중국산 LLM을 파인튜닝한 것도, 기존 오픈소스를 복제한 것도 아닙니다.
베이스 모델 설계부터 학습 데이터 수집, Pre-training 파이프라인, Post-Training 튜닝까지— 모든 과정을 내부에서 직접 설계하고 실행한, 말 그대로 가내수공업 수준의 독자 개발입니다.
7B와 21B 모델은 Preference Tuning이 완료된 상태로 즉시 실사용이 가능하며, 70B-preview 모델은 최소한의 튜닝 상태로 공개되어 사용자가 목적에 맞게 자유롭게 커스터마이징할 수 있도록 설계했습니다. 특히 70B-preview는 국내에서 자체적으로 (from scratch) 로 학습한 모델 중 가장 큰 규모로, 기술적으로도, 오픈소스 생태계 측면에서도 의미 있는 전환점이라 할 수 있습니다.
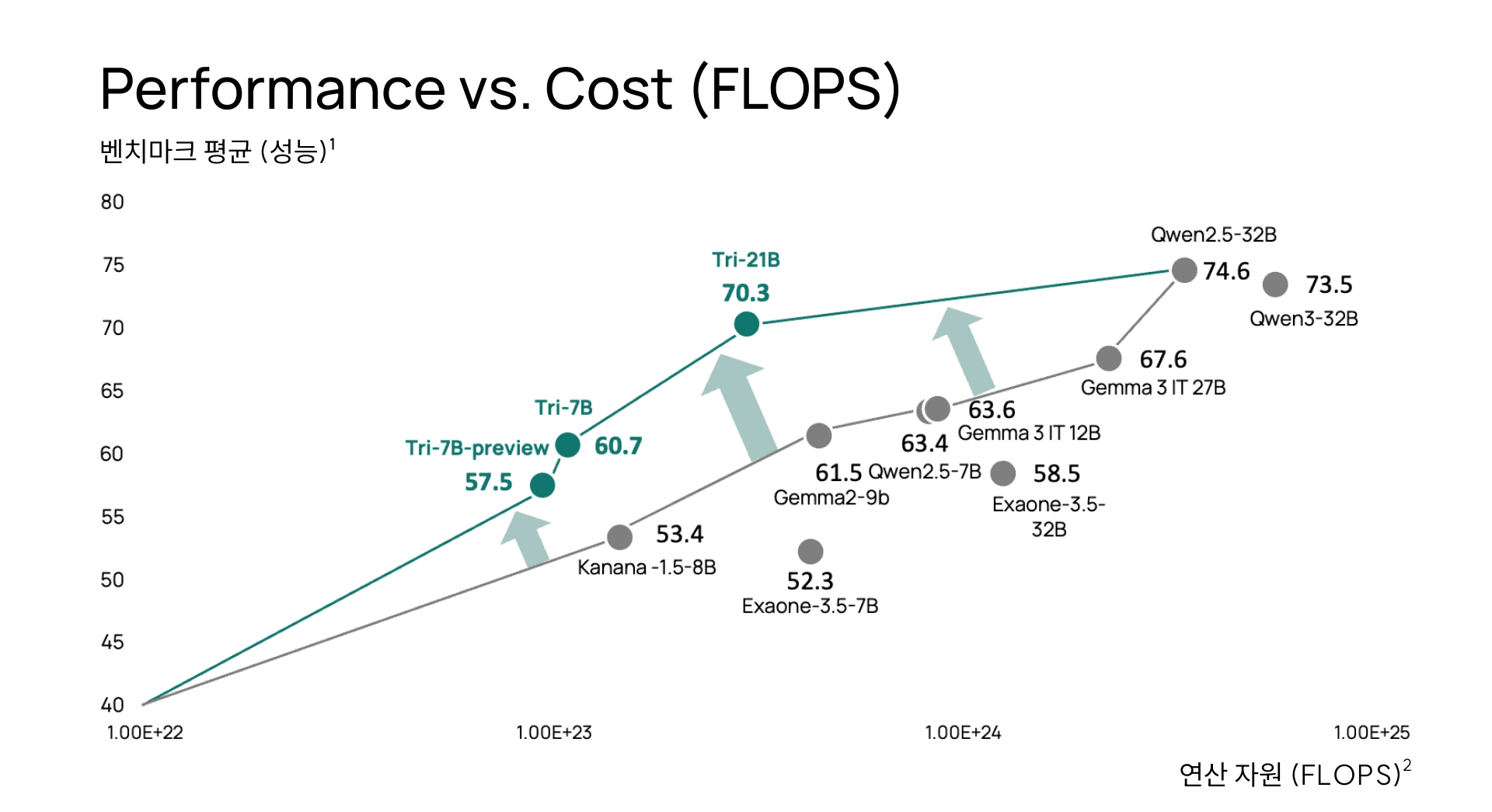
Tri-Series 모델은 학습 효율을 보여주는 FLOP 당 성능 면에서 혁신적인 결과를 보여줍니다. 예를들어, Tri-21B 모델을 유사 규모의 다른 State-of-the-art 오픈소스 모델들과 비교 했을 때, Tri-21B 는 훨씬 적은 Compute resouce (FLOPS) 로 다국어 벤치마크에서 평균 70.3% 의 정확도를 달성했습니다. 주석 (1) MMLU, KMMLU, Global MMLU(일본어)의 평균값 (2) 초당 부동소수점 연산(FLOPs): 모델 파라미터 수와 학습 토큰 수의 곱을 기반으로 산출되는 연산량
Post-training 이 완료된 Tri-7B, Tri-21B 모델은 성능 면에서도 국내 기업이 개발한 LLM 중 최고 수준을 기록하고 있으며, 글로벌 최상위권 프론티어 오픈소스 모델들과도 견줄 만한 성능을 보여주고 있습니다.
예를 들어, Tri-21B 모델은 약 2.95×10²³ FLOPs라는 비교적 적은 계산량 (i.e., 학습 비용)으로 다국어 벤치마크에서 평균 정확도 70.3% 를 달성했습니다. 이는 동급 frontier 모델 중 가장 뛰어난 성능이며, 특히 “얼마나 적은 자원으로 이 성능을 달성했는가”라는 기준에서는 경이로운 수준의 학습 효율성과 구조 최적화의 결과라 할 수 있습니다.
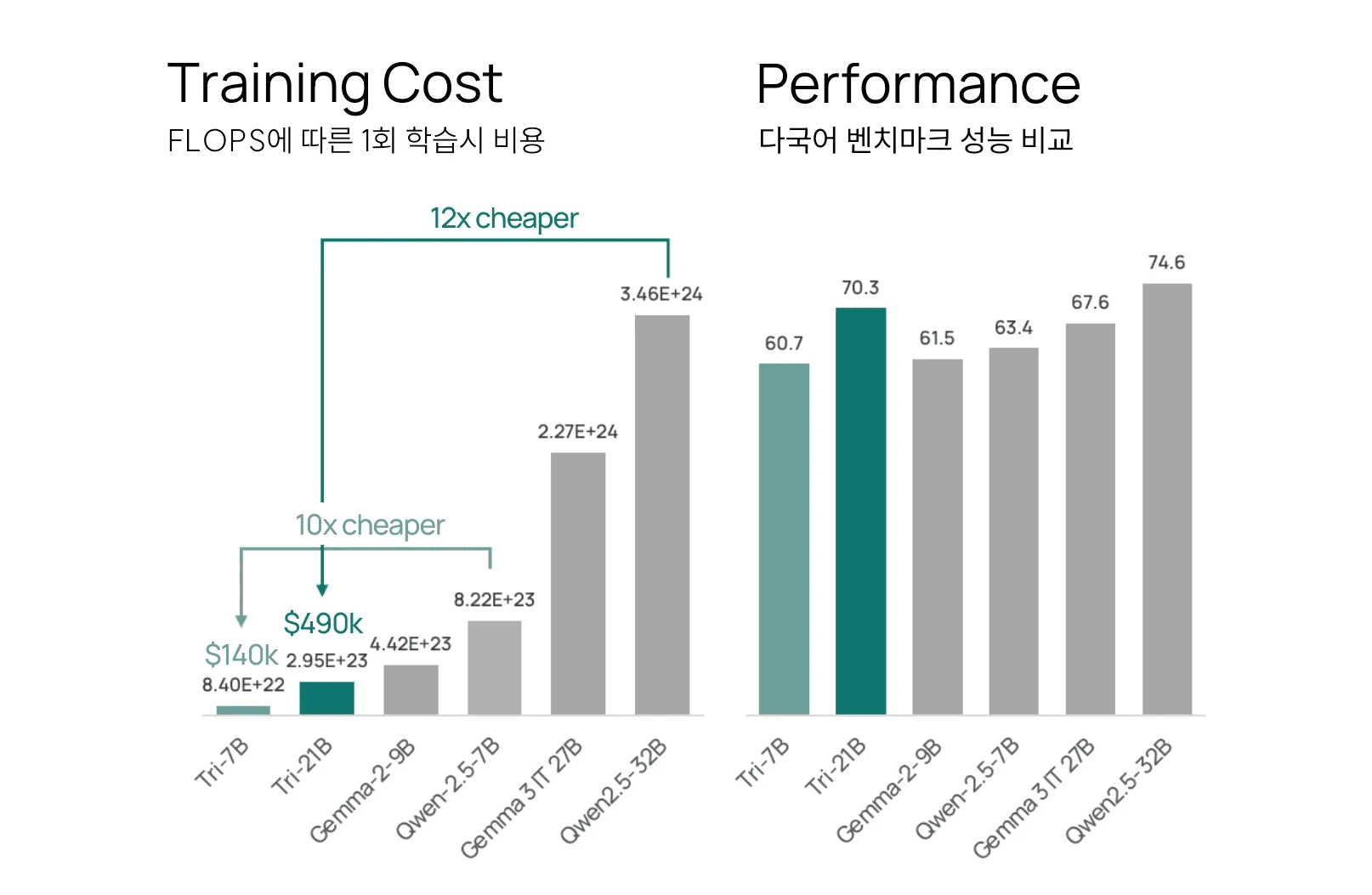
Tri-7B는 1회 학습에 $140K (약 2억), Tri-21B 는 1회 학습에 $490K (약 7억) 으로, 다른 오픈 소스 모델 대비 최대 10~12배 저렴한 비용으로 동일 성능의 모델 구현하였습니다.
이번 글에서는 Trillion Labs가 작은 팀, 제한된 리소스, 그리고 짧은 개발 기간 안에서 어떻게 Tri-Series를 완성했는지, 그 구체적인 기술 전략과 실험 과정을 정리해 공유하고자 합니다. 고품질 데이터 수집, 효율적인 학습 인프라 설계, 한국어에 최적화된 토크나이저, 긴 컨텍스트 학습, Post-Training 전략까지—Trillion Labs가 자체적으로 구축한 LLM 개발 파이프라인 전체를 이 블로그 시리즈에서 자세히 공개합니다.
Pre-Training
학습 인프라 구성
Tri-Series는 HBM3 기반의 NVIDIA H100 GPU 512개로 구성된 클러스터에서 학습되었습니다. HFU(Hardware FLOPs Utilization)는 약 47%, MFU(Model FLOPs Utilization)는 약 43% 수준의 자원 효율을 달성했습니다. 물론 모델 크기가 커질수록 효율이 소폭 하락하는 경향은 있었지만, 전체적으로는 매우 안정적인 학습 환경이 구축되었습니다.
데이터 파이프라인
데이터의 양과 질은 LLM 성능을 결정짓는 가장 핵심적인 요소입니다. 특히 한국어의 경우, 영어에 비해 공개된 웹 크롤링 데이터의 양과 질이 모두 낮은 편으로, 국내 팀들이 모델 학습 과정에서 어려움을 겪는 경우가 많습니다.
Trillion Labs 역시 이 문제를 중요하게 인식하고, Tri-Series 개발 초기부터 대규모 고품질 데이터 확보에 가장 많은 시간과 리소스를 집중했습니다.
Tri-Series 전체 학습에는 총 약 2조 개 토큰의 데이터가 사용되었으며, 학습 효율과 데이터 품질을 극대화하기 위해 아래와 같은 전략을 적용했습니다:
⬥ 동적 데이터 믹스 (Dynamic data mixture)
초기에는 전체 학습 데이터 중 약 15%를 수학 및 코드 중심 데이터로 구성하고, 훈련이 진행될수록 이 비율을 점진적으로 늘렸습니다. 초기부터 기술적 데이터에 치우칠 경우, 전반적인 언어 표현 능력이 저하되는 문제가 있었기 때문에 먼저 일반 자연어 처리 능력을 안정적으로 확보한 뒤, 수학·프로그래밍·추론 등 고난도 기술 도메인에 대한 학습을 점진적으로 강화할 수 있도록 설계하였습니다.
⬥ OCR 기반 고품질 PDF 데이터 수집
고품질 시드 데이터를 확보하기 위해, 개방형 라이센스 (Permissive license)를 가진 과학·수학 관련 PDF 문서를 OCR로 처리하여 텍스트를 수집했습니다. 먼저 사람이 주요 학문 분야를 직접 선정하고, 그 분야를 기준으로 LLM을 활용해 초급부터 고급 수준까지 다양한 난이도의 키워드를 자동 확장했습니다. 이 과정에서 수십만 개의 타겟 키워드를 생성, 고품질 과학·수학 문서를 선별해 데이터셋으로 구축하였습니다.
⬥ LLM 기반 데이터 재작성 (re-writing) 및 정제
수집한 PDF 데이터는 OCR을 거치면서 깨진 수식, 엉킨 표, 불분명한 캡션 등 다양한 품질 저하 요소를 포함하고 있었습니다. 이를 해결하기 위해 Trillion Labs는 Llama-3-70B, Qwen-2.5-72B 등 고성능 오픈소스 LLM을 활용하여 데이터를 대규모로 재작성(rewriting) 하였습니다.
재작성 형식은 단순 문장 복원이 아닌,
사람 간 대화형
Q&A형
설명 중심의 Chain-of-Thought 문제 형식
등 다양하게 구성하여, 같은 데이터라도 여러 구조로 표현될 수 있도록 만들었습니다.
이러한 재작성 방식은 동일한 데이터를 여러 번 학습하더라도 성능 향상을 가져옵니다. 결과적으로, 데이터의 품질과 유용성이 크게 향상되어, 학습 과정에서 더 나은 결과를 얻을 수 있게 됩니다.
커스텀 토크나이저: 한국어, 일본어 최적화
토크나이저(tokenizer)는 텍스트를 모델이 이해할 수 있는 단위로 나누고, 이를 숫자로 변환하는 전처리 단계입니다. 같은 문장이라도 토크나이저의 설계 방식에 따라 토큰 수가 달라질 수 있으며, 이는 곧 모델의 성능과 효율에 직접적인 영향을 줍니다.
실제로 대부분의 LLM API 서비스는 토큰 기준으로 과금되기 때문에, 토크나이저의 효율이 곧 모델 활용 비용을 결정하게 됩니다. 하지만 기존의 많은 토크나이저는 영어 중심의 대규모 코퍼스를 기반으로 학습되어, 한국어나 일본어 같은 형태소 기반 언어에서는 비효율적인 토큰화가 발생하기 쉬웠습니다.
Trillion Labs는 이러한 문제를 해결하기 위해, 한국어와 일본어를 고려한 커스텀 토크나이저를 새롭게 설계했습니다. 전체 vocabulary의 약 30%를 한국어·일본어에 배정하고 각 언어가 동일한 문서 수에서 학습되도록 설정하여 영어·한국어·일본어 간 토큰화 효율의 균형을 맞췄습니다.
이를 통해 Trillion Labs는 다국어 모델에서 자주 발생하는 비영어권 언어의 토큰 비효율 문제를 효과적으로 개선할 수 있었습니다. 실제 벤치마크 결과에서도 Tri-21B 모델은 한국어 자연어 처리 및 추론 관련 과제(KMMLU, KoBEST 등)에서 영어권 중심 오픈소스 모델보다 더 높은 효율을 보였으며, 특히 한국어 prompt에 대한 추론 속도를 LLama 대비 33% 개선했습니다.
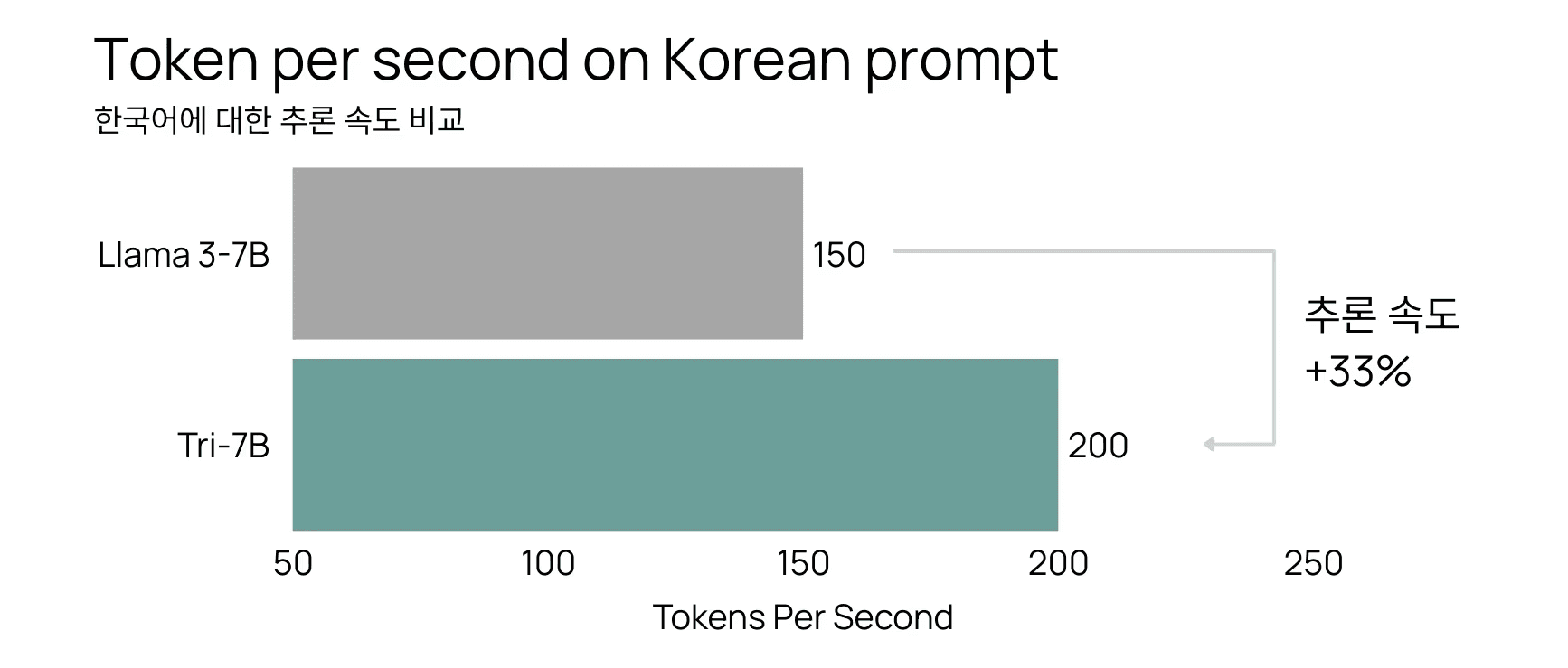
한국어 프롬프트에서 Llama 3-7B 대비 Tri-7B의 토큰당 초 추론 속도 비교하였을 댸, Tri-7B가 200 TPS 로 Llama 3-7B(150 TPS)보다 33% 더 빠른 속도를 보였습니다.
4. 아키텍처 설계
Tri-Series 모델은 긴 텍스트 이해와 복잡한 작업 수행 능력을 극대화하기 위해 Multi-Token Prediction(MTP)을 핵심 아키텍처 요소로 채택하고, SSMax와 iRoPE를 통합하여 고효율, 고성능 AI 구현을 위한 최적화된 설계를 선택했습니다.
⬥ Multi-Token Prediction
Tri-Series 모델에는 Multi-Token Prediction(MTP)이 활용되었습니다. MTP는 모델이 한 번의 추론 단계(next step)에서 단 하나의 토큰(단어)만 예측하는 기존 방식과 달리, 여러 개의 토큰을 한 번에 예측하도록 설계된 방식입니다.
구분 | 기존 방식 (Single Token) | MTP 방식 (Multi-Token) |
|---|---|---|
입력 | "나는 오늘" | "나는 오늘" |
예측 | "점심" (1단계) | "점심을 먹으러" (1단계) |
추론 과정 | 한 번의 단계에서 한 개 토큰 예측 | 한 번의 단계에서 여러 토큰 예측 |
학습 효율 | 상대적으로 낮음 | 동일 데이터로 여러 번의 학습 신호 부여 |
MTP는 추가 레이어와 고비용의 Softmax 연산을 수행해야 하므로 학습 속도가 약 10% 정도 느려집니다. 그러나 이러한 비용에도 불구하고, MTP를 적용한 모델은 모든 벤치마크 테스트에서 유의미한 성능 개선을 보여주었습니다.
MTP의 가장 큰 장점 중 하나는 학습 효율이 올라간다는 점입니다. 동일한 입력 데이터를 사용하더라도 한 번에 여러 개의 토큰에 대한 예측 목표를 설정함으로써, 모델에 여러 번의 강력한 학습 신호(Training Signal)를 제공합니다. 이는 모델이 문장 구조와 문맥을 더 깊이 이해하고 빠르게 학습할 수 있도록 돕습니다.
요약하자면, MTP는 약간의 학습 속도 희생을 감수하는 대신, 압도적인 성능 개선과 학습 효율 증대라는 핵심 이점을 제공합니다.
⬥ SSMax + iRoPE
70B 모델에는 LLM이 아주 긴 글도 문제없이 이해하고 처리할 수 있도록 도와주는 두 가지 기술이 적용 되었습니다.
SSMax는 긴 컨텍스트 길이를 효율적으로 처리하기 위한 Softmax 대체 구조로, 글의 길이가 아무리 길어져도 AI가 지치지 않고 빠르게 처리할 수 있습니다.
iRoPE는 RoPE 계열 포지셔널 인코딩의 개선형으로, 쉽게 말하면 AI가 문장 속에서 단어의 '위치'와 '순서'를 헷갈리지 않고 정확하게 기억하도록 돕는 설계입니다.
다음 편에서는 실제 Pre-training 단계에서 효율적이고 안정적인 학습을 가능하게 하는 방법을 다룰 예정입니다. 특히, 적은 데이터만으로도 한국어에 특화된 고성능을 발휘하는 XLDA와 Data recipe 평가의 비용을 최대 100배 이상 효율화 시키는 rBridge 에 대해 소개할 예정입니다.
Tri-Series를 직접 사용해보세요
Tri-Series는 Hugging Face를 통해 전 모델이 공개되어 있습니다. 실험, 연구, 튜닝, 커스터마이징까지 자유롭게 활용하실 수 있습니다.
Read more from our blog


Join our newsletter
Get the latest AI news and insights every week