March 18, 2025
Model Release
Introducing Tri-7B

We introduce Tri-7B-preview, a preview of our latest large language model designed to push the boundaries of multilingual scalability and performance.
With a novel architectural technique—Cross-lingual Document Attention (XLDA)—Tri‑7B-preview bridges the gap between high-resource and low-resource language modeling. Tri-7B-preview delivers strong multilingual performance while remaining remarkably compute- and token-efficient.
Performance at the Efficiency Frontier
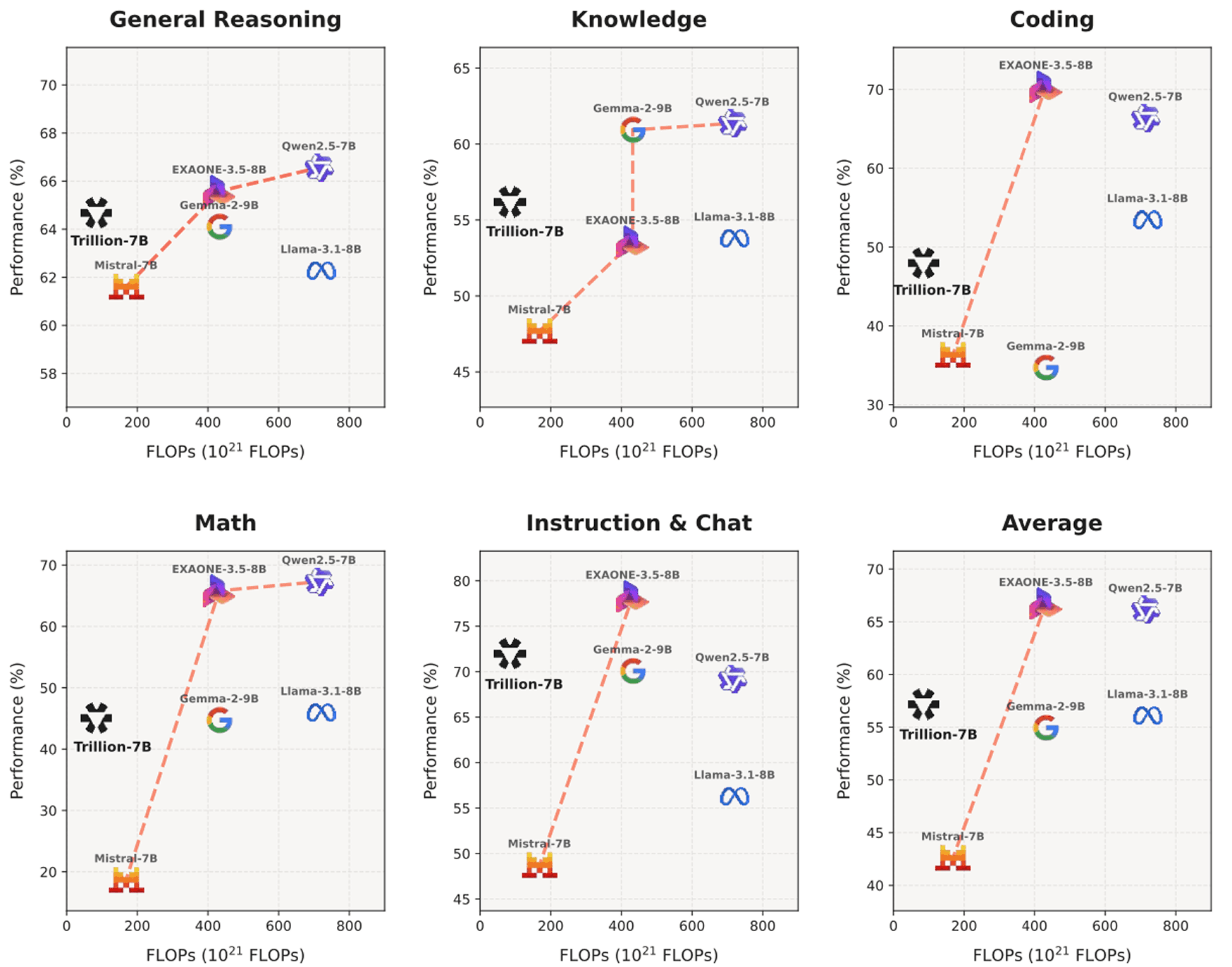
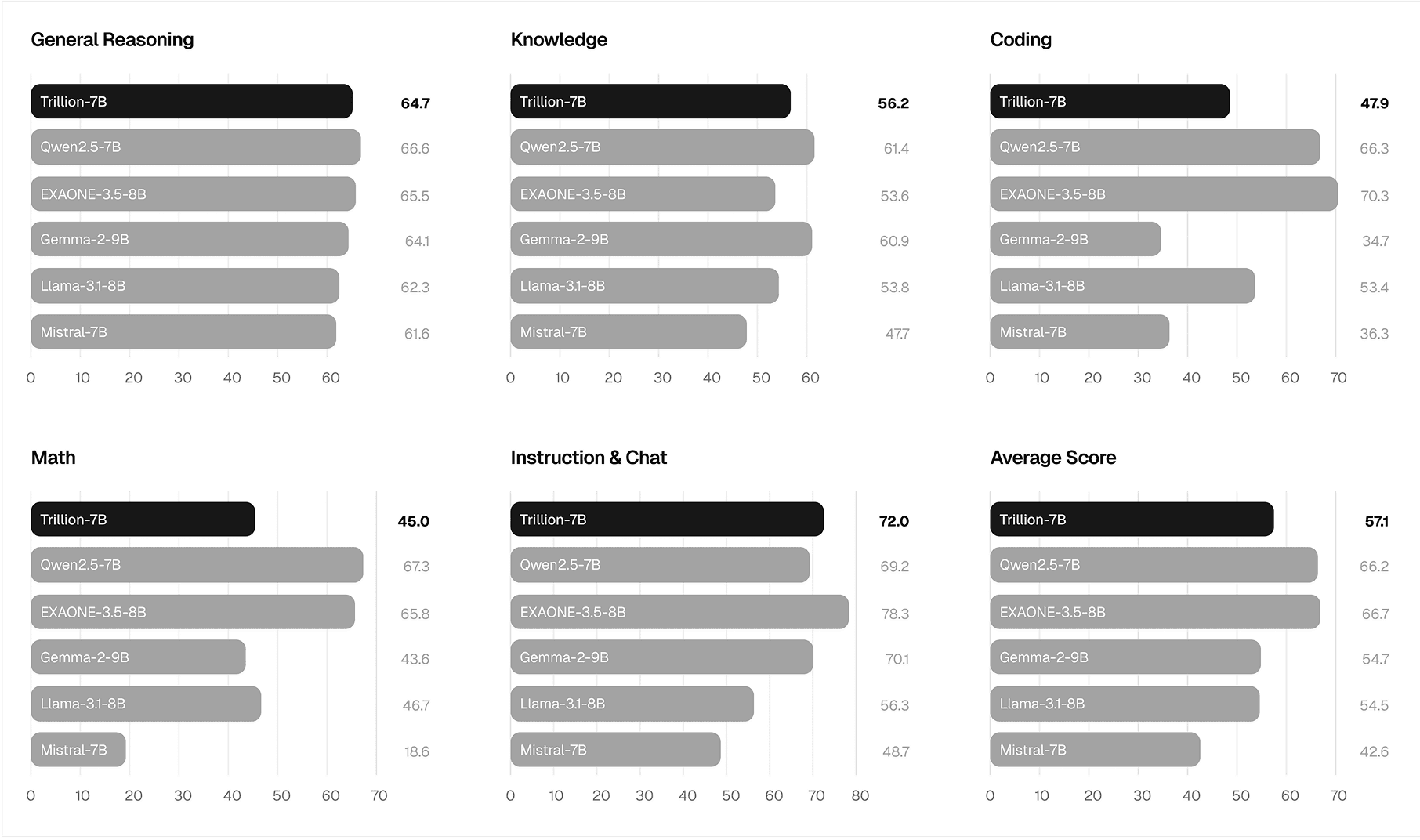
Tri-7B significantly advances the compute Pareto-frontier across all aspects.
When comparing performance to training FLOPs for Tri-7B-preview with competitive models, our model pushes the Pareto frontier, achieving around 55.7% average performance while using significantly fewer compute (~9.3×10²² FLOPs). It outperforms models like Mistral-7B-Instruct-v0.3 and SOLAR-10.7B-Instruct-v1.0 while remaining competitive with models requiring 3-8× more compute such as Qwen2.5-7B-Instruct and EXAONE-3.5-7.8B-Instruct. In dollars, our compute cost is equivalent to approximately 59.4K H100 GPU Hours, approximately 148K USD, illustrating extreme compute effficiency of our approach.
A Closer Look: Cross-lingual Document Attention (XLDA)
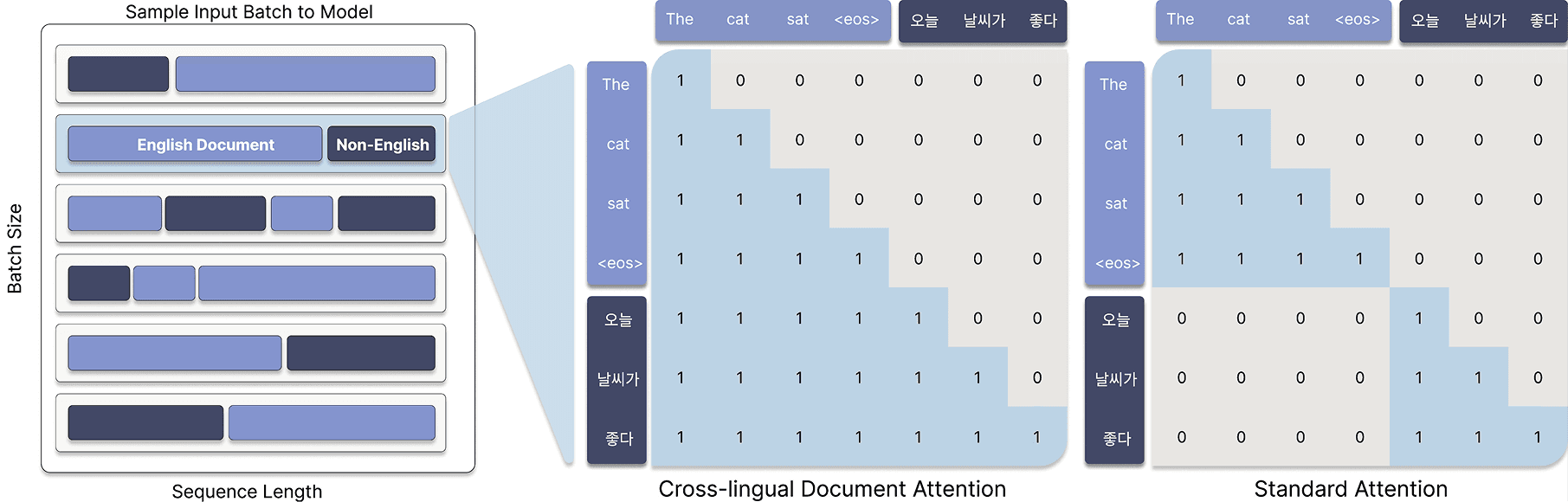
Illustration of Cross-lingual Document Attention (XLDA).
At the heart of Tri-7B’s multilingual strength lies Cross-lingual Document Attention (XLDA), a lightweight architectural technique that facilitates cross-lingual knowledge transfer—without requiring massive multilingual corpora.
XLDA operates through a combination of strategic document packing and selective attention masking. During training, each sequence is intentionally composed of content from multiple languages—typically English and a target language like Korean—so the model can observe cross-lingual patterns within the same context window. Instead of blocking attention across document boundaries, XLDA allows tokens from different languages to attend to each other, enabling the model to connect semantically related content across languages.
Robust Multilinguality: Cross-lingual Consistency
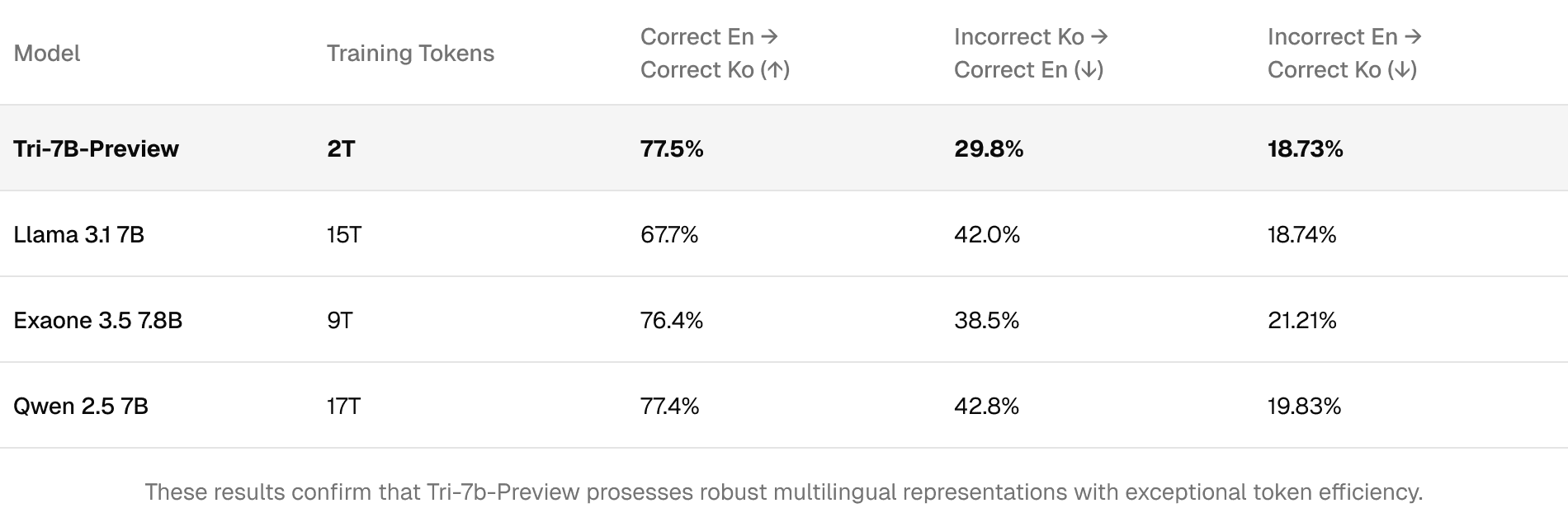
We evaluated how well knowledge transfers between languages using parallel English-Korean question sets from Global-MMLU. Our primary metric measures whether correct English predictions lead to correct Korean predictions.
Tri-7B achieves 77.5% cross-lingual consistency, matching Qwen 2.5 7B while using 8.5× fewer training tokens and significantly outperforming Llama 3.1 7B (67.7%).
These results confirm that Tri-7b-Preview prosesses robust multilingual representations with exceptional token efficiency.
Generalization to Vision
Tri-7B's multilingual foundation extends beyond text to vision-language tasks. We fine-tuned our model into a Vision Language Model (VLM) using LLaVA's training framework, training exclusively on English vision-language instruction pairs.
Despite English-only vision training, Trillion-LLaVA shows remarkable zero-shot Korean visual reasoning performance, significantly outperforming other 7B VLMs on Korean benchmarks:
This demonstrates that robust multilingual pre-training enables effective transfer of visual reasoning across languages without language-specific visual training data, potentially streamlining multilingual vision-language system development.

Try Out Tri-7b-Preview Today!
To explore Tri‑7B-Preview in greater depth:
🤗 Hugging Face Model Card: Tri-7B-Preview on Hugging Face
📄 Technical Report: Read the full architecture and training methodology in our Tri-7B Technical Report
We look forward to community feedback and collaboration as we continue expanding the frontiers of multilingual AI.
Read more from our blog


Join our newsletter
Get the latest AI news and insights every week