Feb 6, 2026
Publication
gWorld: The first-of-its-kind mobile world model

TL;DR — "What happens when I tap this button?" gWorld is an open-source mobile world model that predicts the next phone screen as HTML/CSS code. A single 8B model beat models 50x larger*.
What if an AI could look at your phone screen, watch you tap a button, and accurately predict what the screen will look like after the tap — before it even happens? That's the core promise of mobile world models, and it's more useful than it sounds.
If you've followed the recent wave of world models — from to Google’s Project Genie — you already know the basic idea: train a model to predict what happens next in some environment, given the current state and an action. The same concept applies to your phone. A mobile world model takes a screenshot and an action (say, tapping coordinates [350, 720]) and predicts the resulting screen state. Get this right, and you can simulate entire interaction sequences without ever touching a real device — which turns out to be enormously valuable for training AI agents that operate phones.
The problem is that current approaches to mobile world modeling are stuck between two bad options. Text-based world models throw away visual information — layout, color, typography — reducing rich interfaces to flat descriptions. Image-generation models try to hallucinate pixels directly, but they butcher text rendering and struggle with the precise, structured nature of mobile UIs. Neither is great.
At Trillion Labs, we built gWorld to escape this trade-off entirely. Instead of generating text descriptions or raw pixels, gWorld predicts the next screen state as renderable web code — valid HTML and CSS that a browser can display. It's a surprisingly natural fit: Vision-Language Models (VLMs) already understand structured code from pre-training, and web code preserves every visual detail — pixel-perfect text, exact layouts, proper iconography — that pixel generators fumble.
The result? gWorld 8B and 32B achieve better accuracy-per-parameter than any existing open-weight model — outperforming alternatives up to 50x larger across six benchmarks. And the models, data pipeline, and benchmarks are all publicly available under Apache 2.0.
Why Predicting the Next Screen Matters
Mobile world models solve real bottlenecks in building phone-operating AI agents.
In 2026, tools for AI-powered device control are everywhere. OpenClaw with 240K GitHub stars, Anthropic's Claude Computer Use, Manus AI. But if you've actually used them, you know — they're slow, and they get it wrong a lot* Each action requires a screenshot capture → VLM inference → action execution loop. Anthropic itself admits in its documentation that "latency is currently too slow for general use." Beyond speed, the deeper problem is the cost of wrong actions — when an agent taps the wrong button, it's hard to undo and sometimes impossible.
Making these agents smarter requires large-scale training, but the training environment itself is the bottleneck. Training an agent to navigate mobile apps is expensive and risky. Real interactions are slow — each action requires waiting for an emulator response, creating a 1:1 coupling between GPU and device that's a scalability nightmare. Worse, some actions are irreversible: you don't want your agent accidentally confirming a financial transaction during training.
A world model sidesteps both problems. If you can accurately simulate what happens after each action, you can train agents in imagination — generating synthetic trajectories without touching a real device. This unlocks massively parallel rollouts, safe exploration of risky actions, and a path toward reinforcement learning at scale for GUI agents.
But the world model has to be good enough. If it hallucinates wrong text, distorts layouts, or fails to reflect the actual consequences of an action, the downstream agent learns from garbage. Visual fidelity isn't optional.
Where Pixel Generation Flops
Before gWorld, the most ambitious attempt at visual mobile world modeling was VIMO, which uses a custom-trained diffusion model to generate next-state images. VIMO proved that visual world models outperform text-only ones. But it came with serious baggage.
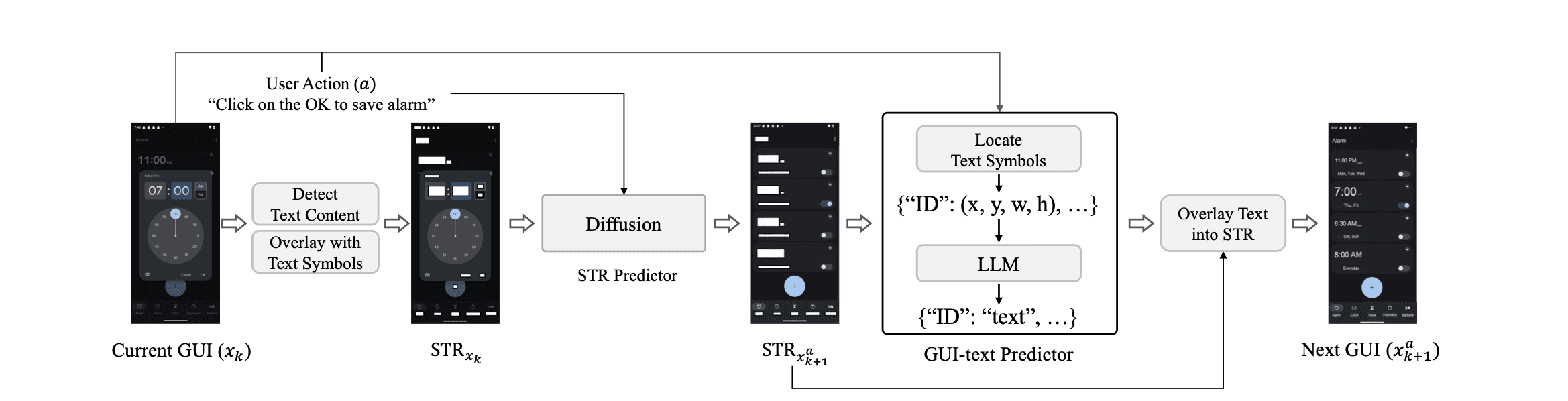
VIMO's pipeline requires five separate models working in concert: an OCR system for text detection, a box-based text masking module, GPT-4o for filtering and text infilling, and a custom diffusion model for image generation. That's a complex, slow, and expensive pipeline — and the diffusion model weights were never released.
More fundamentally, image-generation models have a structural weakness for mobile GUIs. Phone screens are highly redundant — a tap might change a single toggle or open a small menu while 90% of the screen stays identical. Image-gen models exploit this by learning a trivial strategy: copy the input image with minor modifications. They score well on perceptual similarity metrics while failing to capture what actually changed.
We confirmed this quantitatively. When we measured how strongly output quality correlates with input-output similarity (Pearson ρ), image-generation models scored above 0.9 — almost perfect correlation, meaning their accuracy depends entirely on how similar the before and after screens already are. gWorld's correlation is roughly 0.4. It's actually modeling what changed, not copying what didn't.
The Core Idea: Code as Visual Representation
gWorld's key insight is that web code is a better output format than either text or pixels for representing mobile GUI states.
Think about what a phone screen actually is: a structured layout of text, icons, and interactive elements arranged according to precise spatial rules. That's essentially what HTML and CSS describe. By training a VLM to output renderable web code instead of pixel arrays, we get the best of both worlds.
VLMs already have strong priors for generating precise, legible text — something diffusion models notoriously struggle with. Their pre-training on billions of web pages means they understand how to translate visual layouts into structured code. And the output is executable: you render the HTML in a headless browser (roughly 0.3 seconds via Playwright) and get a pixel-perfect screenshot. Less than 1% of gWorld's outputs fail to render — effectively zero structural errors.
The approach also enables something subtle but powerful: the model can generate semantically coherent content, not just layout. When predicting the next state of an email app, gWorld produces plausible email text that fits the context. When navigating a settings screen, toggle labels and option values are contextually appropriate. The linguistic capabilities of the underlying VLM shine through in ways that a pure image generator cannot match.
MWMBench: A Proper Benchmark for Mobile World Models
Existing benchmarks for mobile world modeling had blind spots. They converted actions from coordinates to text (outsourcing spatial understanding to an external model), tested only in-distribution, and evaluated only text-based world representations.
We built MWMBench to fix all three. It spans six data sources across four in-distribution and two out-of-distribution splits, keeps actions in their original coordinate format, and evaluates visual world modeling directly. The out-of-distribution splits are particularly noteworthy: AndroidWorld tests zero-shot generalization on English-language productivity and media apps, while KApps tests generalization to Korean-language interfaces — Baemin, Coupang, KakaoTalk, Naver Map — reflecting real mobile usage patterns in Korea.
The primary evaluation metric, Instruction Accuracy (IAcc), uses a panel of three frontier VLMs as judges to determine whether the generated next state correctly reflects the action applied to the current state. This is more rigorous than pixel similarity alone, which can be gamed by the copy-the-input strategy described earlier.
Results: Small Models, Superior Performance
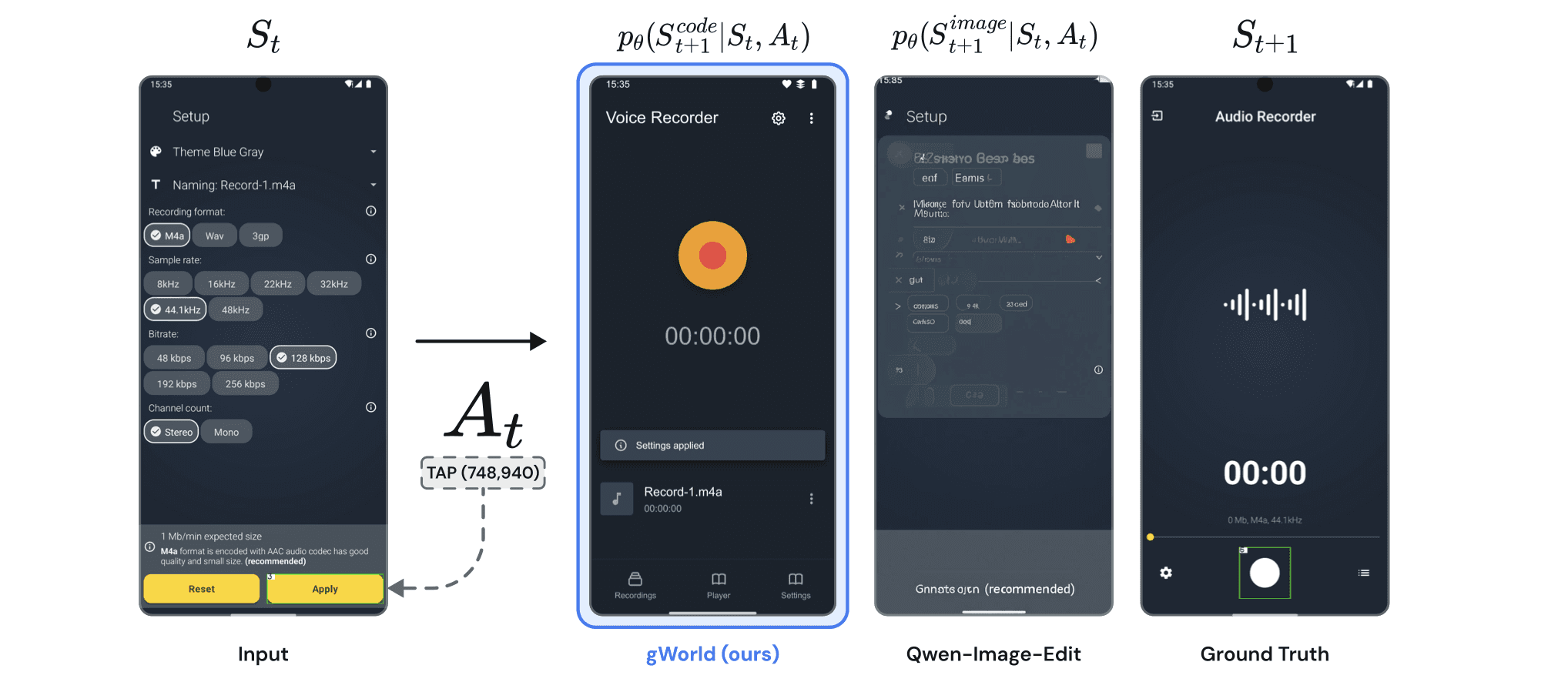
gWorld 32B achieves the highest average Instruction Accuracy across all six benchmarks. gWorld 8B comes in second. Both outperform every frontier open-weight model we tested — including Llama 4 402B (50x larger), Qwen3 VL 235B (29x larger), and GLM-4.6V 106B (13x larger).
The code-based approach virtually eliminates render failures: gWorld's failure rate is below 1%, compared to double-digit failure rates for image-generation baselines. On the out-of-distribution benchmarks, gWorld shows minimal degradation compared to in-distribution performance — strong evidence that the approach generalizes rather than memorizing training distributions.
Scaling analysis reveals something encouraging: performance follows a power law with dataset size (R² ≥ 0.94 across splits), and the curve hasn't saturated. With 3.7 million potential training transitions available from existing datasets — versus the 260K we used — there's substantial headroom for improvement by simply generating more data.
From World Model to Better Agents
The critical question: does a better world model produce better agents? We integrated gWorld into M3A, a mobile agent framework, using breadth-wise rollout with three action candidates. The agent uses gWorld to simulate the outcome of each candidate action, estimates the value of each resulting state, and selects the highest-value action.
Across two backbone policies (Gemini 2.5 Flash and GPT-5 Mini), adding gWorld 8B yielded the largest performance gains over the baseline — +22.4 and +21.8 percentage point average improvements, respectively. A 1 percentage point improvement in world modeling performance translates to roughly 0.49 percentage points of downstream policy improvement. World modeling quality has a direct, measurable impact on agent capability.
Alibaba's Code2World
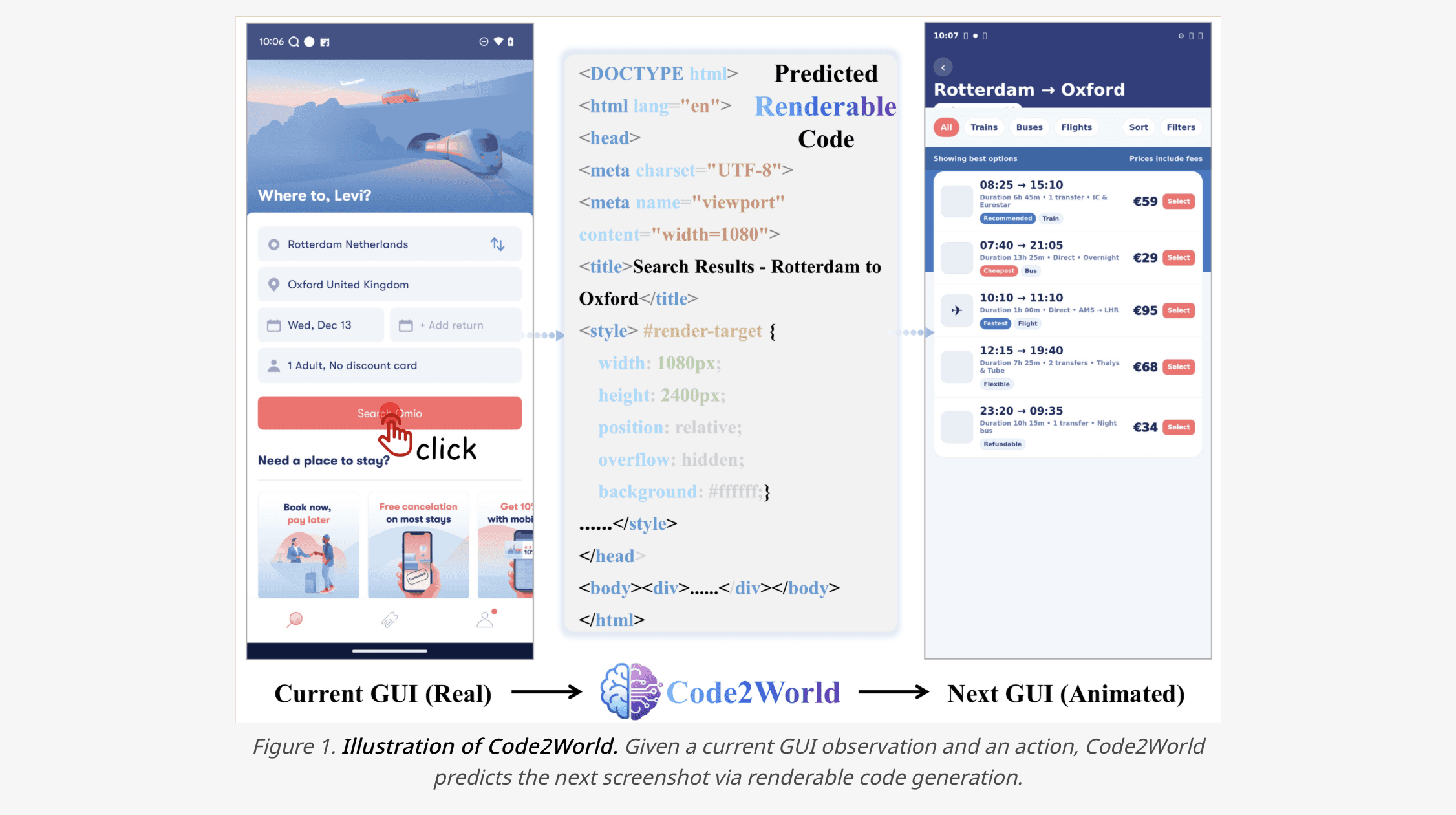
Shortly after gWorld's release, Alibaba's AMAP team published Code2World. The core idea is strikingly similar — approaching GUI world models through renderable HTML code generation, replacing diffusion-based pixel generation with code. Code2World drew significant attention after publication.
We view this convergence not as competition, but as validation. Two independent teams arriving at the same solution at the same time strongly suggests that "code-generation-based GUI world models" are the natural answer to this problem.
Try gWorld
gWorld is available on Hugging Face with models, data pipeline, and benchmarks all under Apache 2.0. Use it freely for research, fine-tuning, or agent integration.
Resources:
Project page: trillionlabs-gworld.github.io
Models: gWorld-8B | gWorld-32B
Benchmark: MWMBench
Read more from our blog


Join our newsletter
Get the latest AI news and insights every week