Research
Introducing rBridge
The Most Efficient Path to Pre-training a Reasoning Model

TL;DR: We introduce rBridge, a methodology that enables tiny proxy models to reliably predict the reasoning performance of much larger models, reducing the cost of pre-training data and hyperparameter optimization by over 100 to 700×. You can find the paper here.
Introduction
At Trillion Labs, we believe that the path to AGI is not brute-force scale, but efficiency. The most important breakthroughs in AI will not come from simply training larger models, but from discovering how to unlock frontier-level reasoning with radically less compute.
Today, reasoning remains one of the most expensive capabilities to develop. In modern pre-training workflows, researchers rely on small proxy models—cheap, small-scale models trained on candidate data mixtures—to estimate how a much larger target model will behave. These proxies are essential for iterating on data recipes before committing to full-scale training.
For reasoning, however, small proxy models fail to predict downstream performance. Meaningful proxy models need to operate at 7B parameters or more—but models at this scale are prohibitively expensive to iterate on.
rBridge changes this equation. By enabling tiny proxy models (≤1B parameters) to reliably predict the reasoning performance of models 13× to 32× larger, rBridge collapses the cost of pre-training optimization by over 100×. What once required millions of dollars and months of training can now be explored quickly, cheaply, and rigorously—opening a fundamentally more efficient path to reasoning-capable AI.
Small Models Give the Wrong Signal
In pretraining, the data recipe is arguably the most critical factor determining a model's final capabilities. Researchers rely on small proxy models to compare and rank candidate datasets before committing to large-scale training. For general language capabilities, this strategy works well: performance improvements observed in 100M-parameter models typically extrapolate reliably to models at 7B parameters and beyond.
Reasoning breaks this assumption. Unlike pattern matching or factual recall, reasoning capabilities exhibit emergent behavior. They simply don't appear until models reach sufficient scale, typically 7B parameters or larger. This creates a painful catch-22: to know if your pre-training data will produce a model that can reason well, you have to actually train a large, expensive model.
Our experiments confirm this challenge. When we tracked MATH500 accuracy across pre-training progress:
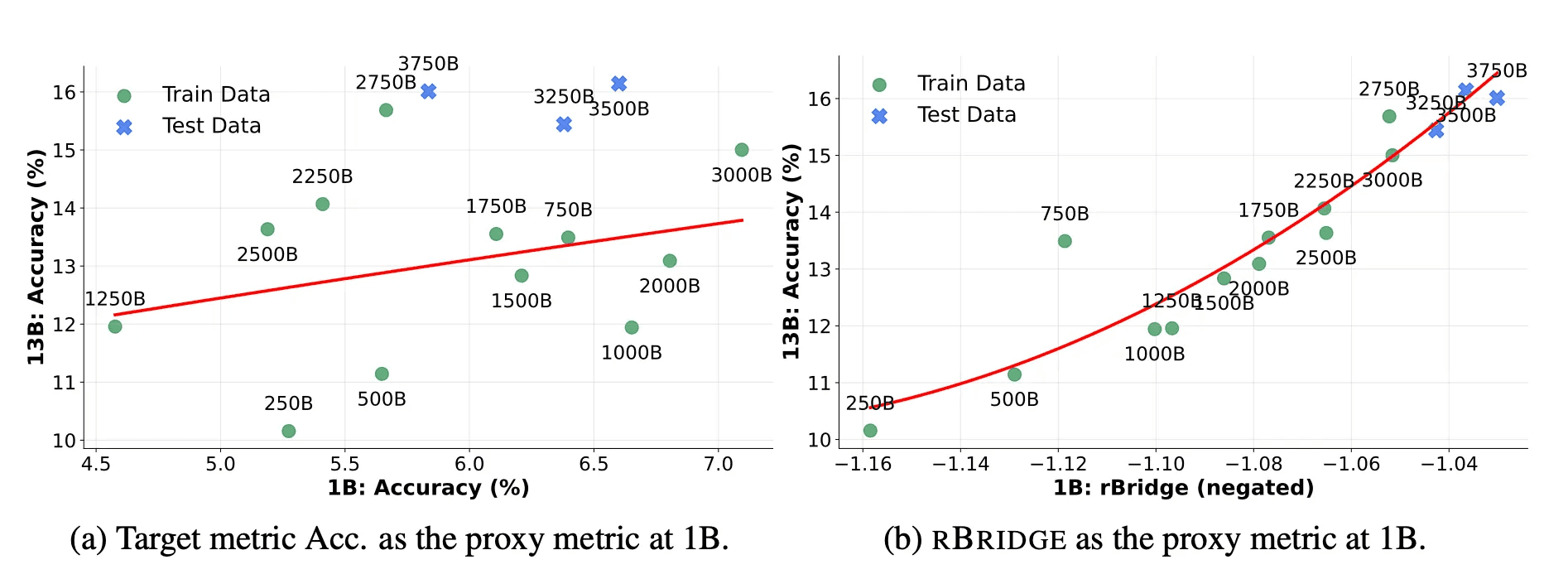
1B models: R² = 0.074 (essentially random noise)
32B models: R² = 0.830 (clear, predictable improvement)
The smaller model's performance curve actually slopes in the wrong direction—making it useless as a proxy for larger model behavior.
rBridge: Making Tiny Models Predict Big Ones
rBridge solves this problem through a deceptively simple insight: small models fail as proxies not because they lack capability, but because we're evaluating them wrong.
Traditional evaluation metrics like accuracy or Pass@K are fundamentally misaligned with what small pre-trained models actually learn. These models are trained on next-token prediction—but we evaluate them on task completion. This mismatch amplifies noise at small scale.
rBridge achieves alignment along two critical axes:
1. Alignment with the Pre-training Objective
Instead of measuring accuracy, rBridge evaluates models using negative log-likelihood (NLL) on reasoning traces generated by frontier models. This stays true to what the model was actually trained to do: predict the next token.
Critically, we found that what you compute NLL on matters enormously. Reasoning traces from frontier models are 74.7% more in-distribution than standard benchmark labels—providing dramatically cleaner signal at small scale.
2. Alignment with the Target Task
Not all tokens in a reasoning trace are equally important. "Sum modulo 9" is crucial for solving a math problem; newlines and formatting are not. rBridge automatically weights each token by the frontier model's confidence in that token:
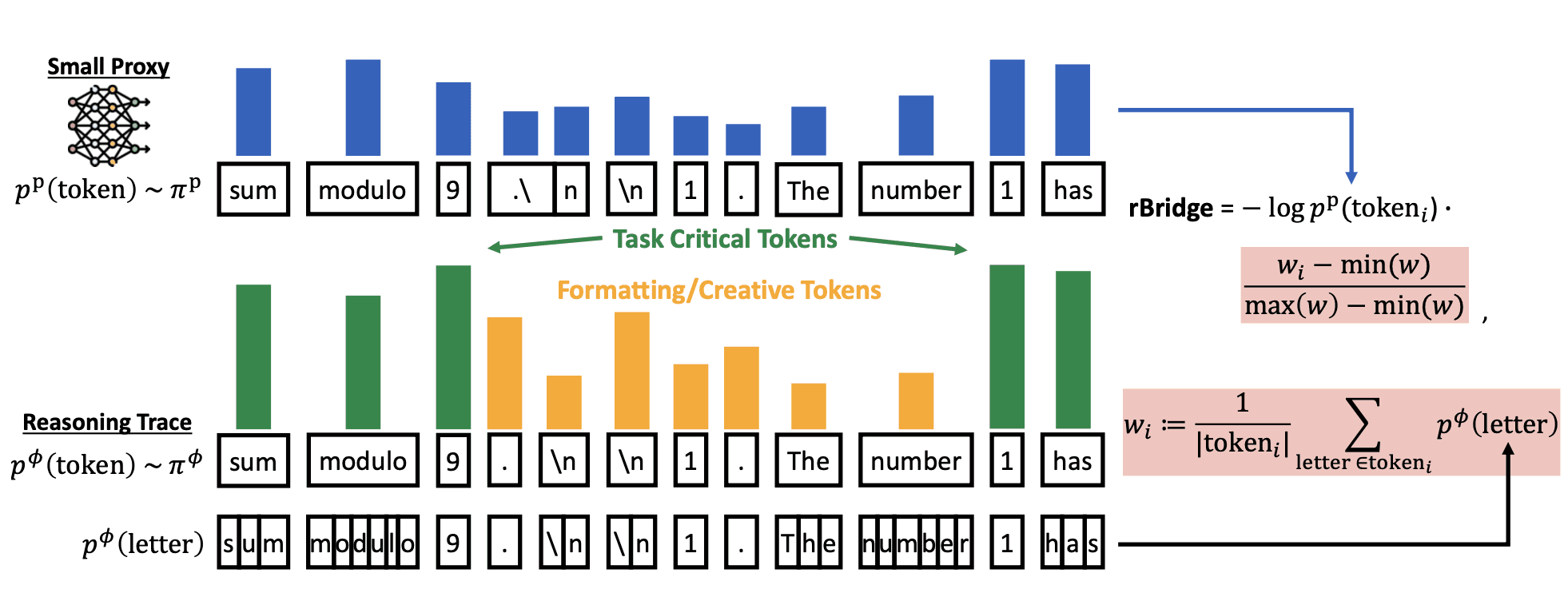
This focuses evaluation on the tokens that actually matter for reasoning, filtering out noise from stylistic choices.
Results: 100× Cheaper, Equally Predictive
The empirical results exceed our expectations:
1. Dataset Ranking at Minimal Scale
Using proxy models as small as 3.7M parameters (324× smaller than the 1.2B target), rBridge achieves 80.8% decision accuracy in ranking pre-training datasets—outperforming all baselines by significant margins.
To achieve equivalent performance, alternative methods require 100× to 733× more compute.
2. Predicting Large Model Performance
At 1B → 13B and 1B → 32B scale:
Average R² of 0.87 across six reasoning benchmarks (math, science, engineering, commonsense, coding)
Test MAE of just 1.38 percentage points
Consistently outperforms proxy models 7-13× larger using traditional metrics
3. Zero-Shot Transfer Across Datasets
Perhaps most remarkably, the relationship between rBridge scores and large model performance transfers zero-shot to entirely new pre-training datasets. Once you've established the mapping on one dataset, you can predict performance on any number of alternative datasets without additional large-scale training.
This enables a practical two-stage optimization framework:
Stage 1: Filter N candidate datasets down to k using tiny (<100M) proxy models
Stage 2: Precisely rank the remaining k datasets using 1B proxies
The cost savings scale with the size of your candidate space—exactly where it matters most.
Why This Matters
The implications for AI development are profound:
For Research Labs: Explore reasoning-oriented pre-training strategies that were previously cost-prohibitive. Test hypotheses about data composition, quality, and mixture at a fraction of the cost.
For Startups and Academia: Compete on ideas rather than compute budgets. A team with modest GPU resources can now systematically optimize pre-training data for reasoning capabilities.
For the AI Community: Accelerate collective progress by lowering the barrier to meaningful pre-training research. More diverse teams exploring more approaches means faster advancement toward beneficial AI.
The Path Forward
rBridge represents a critical step toward democratizing the development of reasoning-capable AI systems. By enabling small proxy models to reliably predict large model behavior, we're reducing the compute barrier that has concentrated AI development among a handful of well-resourced organizations.
This is central to Trillion Labs' mission. We believe the path to beneficial superintelligence requires broad participation—diverse perspectives, distributed innovation, and accessible tools. rBridge is one contribution to that vision.
Our research, methodology, and datasets are open-sourced to support the broader research community. We invite collaboration from researchers worldwide who share our commitment to democratizing AI development.
Paper: Predicting LLM Reasoning Performance with Small Proxy Model
Authors: Woosung Koh, Juyoung Suk, Sungjun Han, Se-Young Yun, Jamin Shin
Affiliations: Trillion Labs, KAIST AI
At Trillion Labs, we're building the infrastructure for the next generation of AI systems. If you're passionate about making advanced AI accessible to everyone, join us.*